
Replicating the information stored on your database is essential for distributing data and ensuring you have a backup that can be used for disaster recovery, in case something goes wrong.
PostgreSQL® replication comes in two forms, and both have their niche uses. Understanding how to apply one or both of these data replication methods can streamline your data distribution processes. The last thing you want is to lose crucial work you’ve done on a database.
Let’s take a look at the pros, cons, and use cases of PostgreSQL logical replication and streaming replication.
Defining Data Replication in PostgreSQL®
If you’re already familiar with what data replication is, then you can go ahead and scroll down to the next section. But in case you’re new to database engineering, we want to set the foundation really quick.
As the name suggests, replication is the process of frequently copying data from one database in a computer server to another database in a different server, so all users have access to the same level of information. In computing, replication is used to eliminate faults in a digital system.
Replication eliminates data silos, protects valuable information, and streamlines development.
In PostgreSQL, there are two options: logical replication & streaming or physical replication. These methods are great for different use cases, and as a developer, you may find yourself more inclined to use one over the other. But it’s good to understand how to use both so you can decide which to apply in different scenarios.
Logical Replication in PostgreSQL®
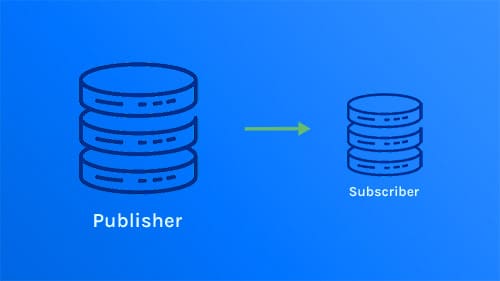
Logical replication was introduced for use with PostgreSQL v10.0. Logical replication works by copying/replicating data objects and their changes based on their replication identity.
In many cases, the data’s replication identity is a primary key. In PostgreSQL, it gives users fine-grained control over the replicated data and information security.
The term logical is used to distinguish it from physical replication, which makes use of byte-by-byte replication and exact block addresses. Read more in the official PostgreSQL documentation here.
Through a publish and subscribe model, it works by enabling one or more subscribers to subscribe to one or more publications on a publisher node. The subscribers can pull information from the publications and re-publish the data for cascading replication or more complex configuration.
Logical data replication can also take the form of transactional replication. If the engineer wants to copy a table, they can use this replication method to take a snapshot of the data on the publisher’s end and send it to the subscriber’s database.
As the subscribers make changes to the original data, the publisher database receives updates in real-time. To ensure transactional consistency in publications with a single subscription, the subscriber must apply the data in the same order as the publisher.
Pros of PostgreSQL® Logical Replication
Logical replication enables users to employ a destination server for writes and allows developers to have different indexes and security definitions. This provides enhanced flexibility for the transfer of data between publishers and subscribers.
Cross-version support
Additionally, logical replication comes with cross-version support and can be set between different versions of PostgreSQL. It also provides event-based filtering. Publications can have several subscriptions, making it easy to share data across a broad network.
Minimum server load
Compared with trigger-based solutions, it has a minimum server load while providing storage flexibility through replicating smaller sets. As mentioned above, logical data replication can even copy data contained in basic partitioned tables.
It’s also essential to mention that logical replication enables data transformation even when it’s being set up and allows parallel streaming across publishers.
Cons of Logical Replication in PostgreSQL®
Logical replication will not copy sequences, large objects, materialized views, partition root tables, and foreign tables.
PostgreSQL logical replication is only supported by DML operations. Developers can’t use DDL or truncate, and the schema has to be defined beforehand. Additionally, it doesn’t support mutual (bi-directional) replication.
If users run into conflicts with constraints on replicated data in a table, replication will stop. The only way for replication to resume is if the cause of the conflict is resolved.
An unintentional conflict can halt your team’s momentum, so you have to understand how to resolve any issues rapidly.
If the conflict isn’t taken care of quickly, the created replication slot will freeze in its current condition, the publisher node will begin accumulating Write-Ahead Logs (WALs), and the node will eventually run out of disk space.
Use Cases for Postgres Logical Replication
Many engineers will use logical replication for:
- Distributing changes within a single database or database subset to subscribers in real-time
- Merging multiple databases into one central database (often for analytics use)
- Creating replications across various versions of PostgreSQL
- Deploying replications between PostgreSQL instances across different platforms, such as Linux to Windows
- Sharing replicated data with other users or groups
- Distributing a database subset between multiple databases
Streaming Replication in PostgreSQL®
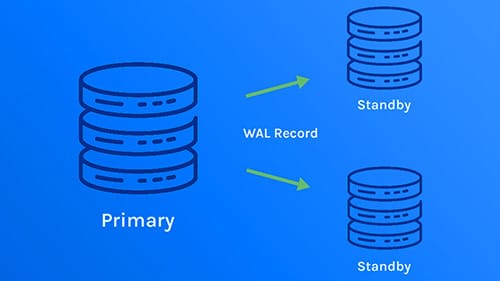
Streaming replication was introduced for use with PostgreSQL 9.0. The process sends and applies Write-Ahead Logging (WAL) files from a master or primary db server to a replica or receiving database. The WALs are used for replication and to ensure data integrity.
How streaming/physical replication works
Streaming/physical replication works to bridge the gap between data transfers inherent in file-based log shipping, which waits until a WAL reaches max capacity to ship data.
By streaming WAL records, database servers stream WAL records in chunks to sync the data. The standby server connects to the replica and receives the WAL chunks as they’re sent over.
With streaming replication, the user has to decide whether to set up asynchronous or synchronous replication. When streaming replication is initially deployed, it will default to asynchronous replication.
This indicates that there is a delay between the initial change on the primary and the reflection of that change on the replica. Asynchronization does open the door for potential data loss if the master crashes before changes are copied or if the replica is so out of sync with the original that it already discarded pertinent data to make changes.
Synchronous replication is a much safer option because it makes changes in real-time. The transfer from the master to the replica is considered incomplete until both servers verify the information. Once the data changes are confirmed, the transfer is recorded on both servers’ WALs.
Whether you use asynchronous or synchronous replication, the replicas must be connected to the master through a network connection. Additionally, it’s essential for the users to set up access privileges for the replica’s WAL streams, so the information isn’t compromised.
Pros of Streaming Replication in PostgreSQL®
One of the most significant perks of using streaming replication is that the only way to lose data is if both the primary and receiving servers crash at the same time. If you’re handing important information, streaming replication all but guarantees that a copy of your work will be saved.
Users can connect more than one standby server to the primary, and the logs will be streamed from the primary to each of the connected standbys. If one of the replicas is delayed or gets disconnected, streaming will continue to the other replicas.
Setting up log-shipping through streaming replication won’t interfere with anything the user is currently running on the primary database. If the primary server has to be shut down, it will wait until the updated records have been sent to the replica before powering down.
Cons of Streaming Replication in PostgreSQL®
Streaming replication will not copy information into a different version or architecture, change the standby servers’ information, and does not offer granular replication.
Especially with asynchronous streaming data replication, older WAL files which are not copied to the replica yet may be recycled when the user makes changes to the master. To ensure that vital files aren’t lost, the user can set the wal_keep_segments to a higher value.
Without user authentication credentials set up for the replica servers, it can be easy for sensitive data to be extracted. For real-time updates to occur between the master and the replica, the user has to change the replication method from the default asynchronous replication to synchronous replication.
Use Cases for Streaming Replication in PostgreSQL®
Many engineers will use streaming replication for:
- Creating a backup for their primary db in case of server failure or data loss
- Fostering a high-availability solution with as little replication delay as possible
- Discharging big queries to relieve some of the stress on the primary system
- Distributing database workloads across several machines, especially for read-only formats
What’s in Store for the Future?
The PostgreSQL Global Development Group announced the release of PostgreSQL 14 on September 30, 2021. The new version came loaded with upgrades in both streaming and logical replications through the platform.
For streaming replication, version 14 enables users to:
- Set the server parameter
log_recovery_conflict_waitsto report long recovery conflict wait times automatically - Pause recovery on a hot standby server when altering the parameters on a primary server (instead of shutting down the standby immediately)
- Use function
pg_get_wal_replay_pause_state()to report the recovery state in more detail - Provide a read-only server parameter
in_hot_standby - Quickly truncate small tables during recovery on clusters that have a large number of shared buffers
- Allow file system sync at the onset of crash recovery through Linux
- Use function
pg_xact_commit_timestamp_origin()on a specified transaction to return the commit timestamp and replication origin - Use function
pg_last_committed_xact()to add the replication origin on the returned record - Employ standard function permission controls to alter replication origin functions (the default still limits access to the superusers)
For logical replication, version 14 enables users to:
- Stream long in-progress transactions to subscribers with the logical replication API
- Permit multiple transactions during table replications
- Generate immediate WAL-log subtransactions and top-level XID associations
- Use function
pg_create_logical_replication_slot()to enhance logical decoding APIs for two-phase commits - Add cache invalidation messages to the WAL during command completion to allow logical streaming of in-progress transactions
- Control which logical decoding messages are sent to the replication stream
- Use binary transfer mode for quicker replications
- Filter decoding by XID
PostgreSQL is already working toward version 15, which is set to be released in the third quarter of 2022. One of the issues regarding replication to be addressed in the newest version includes preventing the use of variables inherited from the server environment in streaming replication. But as more users adapt to version 14, PostgreSQL will likely add more tasks for improving replication functions.
A Quick PostgreSQL® Replication Comparison: Logical vs. Streaming Replication
| Logical Replication | Streaming Replication | |
|---|---|---|
| Model | Publisher to subscriber | Master to replica |
| Transactional Replication | Yes | No |
| Gaps in Replication | A conflict will halt replication | Asynchronous – may cause a delay between data transfer between the primary and replica; synchronous – data is only lost if all connected servers crash simultaneously |
| Replication across different platforms or PostgreSQL versions | Yes | No |
| Security | Data access is limited to subscribers | Must set up access credentials to keep data secure |
| Size of Replications | Better for granular replications | Better for large-scale replications |
| Especially Useful for | Merging multiple systems into one database | Creating a backup database |
Conclusion
We hope this guide comes in handy as you set up your replication functions. Make sure to read our PostgreSQL EXPLAIN article on query costs. If you have any questions or there’s anything else you’d like to know about how ScaleGrid can help you with your PostgreSQL deployments, get in touch with one of our many database experts.



