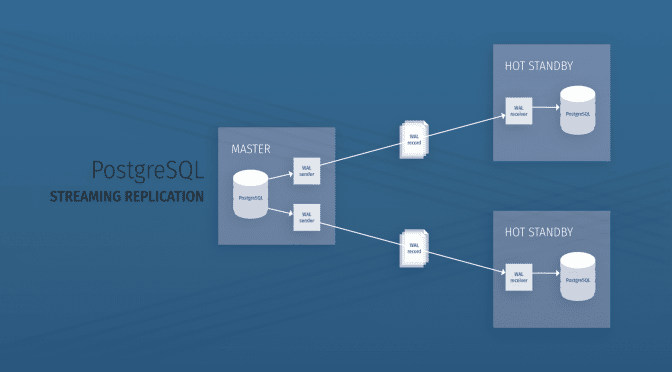
In this blog post, we dive into the nuts and bolts of setting up Streaming Replication (SR) in PostgreSQL. Streaming replication is the fundamental building block for achieving high availability in your PostgreSQL hosting, and is produced by running a master-slave configuration.
Master-Slave Terminology
Master/Primary Server
- The server that can take writes.
- Also called read/write server.
Slave/Standby Server
- A server where the data is kept in sync with the master continuously.
- Also called backup server or replica.
- A warm standby server is one that cannot be connected to until it is promoted to become a master server.
- In contrast, a hot standby server can accept connections and serves read-only queries. For the rest of this discussion, we will be focusing only on hot standby servers.
Data is written to the master server and propagated to the slave servers. In case there are an issue with the existing master server, one of the slave servers will take over and continue to take writes ensuring availability of the system.
WAL Shipping-Based Replication
What is WAL?
- WAL stands for Write-Ahead Logging.
- It is a log file where all the modifications to the database are written before they’re applied/written to data files.
- WAL is used for recovery after a database crash, ensuring data integrity.
- WAL is used in database systems to achieve atomicity and durability.
How is WAL Used For Replication?
Write-ahead log records are used to keep the data in sync between the database servers. This is achieved in two ways:
File-Based Log Shipping
- WAL log files are shipped from the master to the standby servers to keep data in sync.
- Master can directly copy the logs to standby server storage or can share storage with the standby servers.
- One WAL log file can contain up to 16MB of data.
- The WAL file is shipped only after it reaches that threshold.
- This will cause a delay in replication and also increase chances of losing data if the master crashes and logs are not archived
Streaming WAL Records
- WAL record chunks are streamed by database servers to keep data in sync.
- The standby server connects to the master to receive the WAL chunks.
- The WAL records are streamed as they are generated.
- The streaming of WAL records need not wait for the WAL file to be filled.
- This allows a standby server to stay more up-to-date than is possible with file-based log shipping.
- By default, streaming replication is asynchronous even though it also supports synchronous replication.
Both the methods have their pros and cons. Using file-based shipping enables point-in-time recovery and continuous archiving, while streaming ensures the immediate data availability on the standby servers. However, you can configure PostgreSQL to use both methods at the same time and enjoy the benefits. In this blog, we concentrate mainly on streaming replication to achieve PostgreSQL high availability.
How To Set Up Streaming Replication?
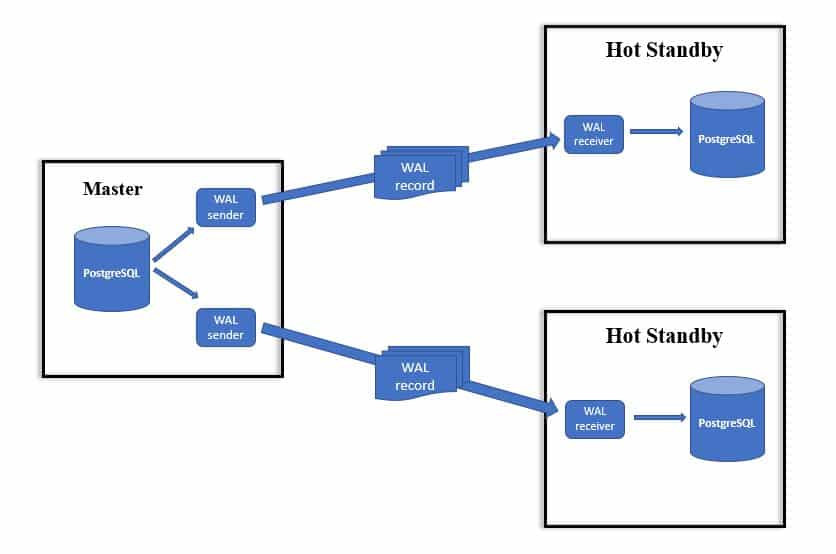
Setting up streaming replication in PostgreSQL is very simple. Assuming PostgreSQL is already installed on all the servers, you can follow these steps to get started:
Configuration on Master Node
- Initialize the database on the master node using initdb utility.
- Create a role/user with replication privileges by running the below command. Post running the command, you can verify it by running \du to list them on psql.
- CREATE USER <user_name> REPLICATION LOGIN ENCRYPTED PASSWORD ’<password>’;
- Configure properties related to streaming replication in the master PostgreSQL configuration (postgresql.conf) file:
# Possible values are replica|minimal|logical
wal_level = replica# required for pg_rewind capability when standby goes out of sync with master
wal_log_hints = on# sets the maximum number of concurrent connections from the standby servers.
max_wal_senders = 3
# The below parameter is used to tell the master to keep the minimum number of
# segments of WAL logs so that they are not deleted before standby consumes them.
# each segment is 16MB
wal_keep_segments = 8
# The below parameter enables read only connection on the node when it is in
# standby role. This is ignored when the server is running as master.
hot_standby = on - Add replication entry in pg_hba.conf file to allow replication connections between the servers:
# Allow replication connections from localhost,
# by a user with the replication privilege.
# TYPE DATABASE USER ADDRESS METHOD
host replication repl_user IPaddress(CIDR) md5 - Restart the PostgreSQL service on the master node for the changes to take effect.
Configuration on Standby Node(s)
- Create the base backup of master node using pg_basebackup utility and use it as a starting point for the standby.
# Explaining a few options used for pg_basebackup utility
# -X option is used to include the required transaction log files (WAL files) in the
# backup. When you specify stream, this will open a second connection to the server
# and start streaming the transaction log at the same time as running the backup.
# -c is the checkpoint option. Setting it to fast will force the checkpoint to be
# created soon.
# -W forces pg_basebackup to prompt for a password before connecting
# to a database.
pg_basebackup -D <data_directory> -h <master_host> -X stream -c fast -U repl_user -W - Create the replication configuration file if not present (it is created automatically if -R option is provided in pg_basebackup):
# Specifies whether to start the server as a standby. In streaming replication,
# this parameter must be set to on.
standby_mode = ‘on’# Specifies a connection string which is used for the standby server to connect
# with the primary/master.
primary_conninfo = ‘host=<master_host> port=<postgres_port> user=<replication_user> password=<password> application_name=”host_name”’# Specifies recovering to a particular timeline. The default is to recover along the
# same timeline that was current when the base backup was taken.
# Setting this to latest recovers to the latest timeline found
# in the archive, which is useful in a standby server.
recovery_target_timeline = ‘latest’ - Start the standby.
The standby configuration has to be done on all the standby servers. Once the configuration is done and a standby is started, it will connect to master and start streaming logs. This will setup the replication and can be verified by running the SQL statement “SELECT * FROM pg_stat_replication;“.
By default, streaming replication is asynchronous. If you wish to make it synchronous, then you can configure it using the following parameters:
| # num_sync is the number of synchronous standbys from which transactions # need to wait for replies. # standby_name is same as application_name value in recovery.conf # If all standby servers have to be considered for synchronous then set value ‘*’ # If only specific standby servers needs to be considered, then specify them as # comma-separated list of standby_name. # The name of a standby server for this purpose is the application_name setting of the # standby, as set in the primary_conninfo of the # standby’s WAL receiver. synchronous_standby_names = ‘num_sync ( standby_name [, …] )’ |
Synchronous_commit must be set to on for synchronous replication and this is the default. PostgreSQL provides very flexible options for synchronous commit and can be configured at user/database levels. Valid values are as follows:
- Off – Transaction commit is acknowledged to the client even before that transaction record is actually flushed to WAL log file on that node.
- Local – Transaction commit is acknowledged to the client only after that transaction record is flushed into the WAL log file on that node.
- Remote_write – Transaction commit is acknowledged to the client only after the server(s) specified by synchronous_standby_names confirms that the transaction record was written to the disk cache, but not necessarily after being flushed to the WAL log file.
- On – Transaction commit is acknowledged to the client only after the server(s) specified by synchronous_standby_names confirms that the transaction record is flushed to the WAL log file.
- Remote_apply – Transaction commit is acknowledged to the client only after the server(s) specified by synchronous_standby_names confirms that the transaction record is flushed to the WAL log file and it is applied to the database.
Setting synchronous_commit to off or local in synchronous replication mode will make it work like asynchronous, and can help you achieve better write performance. However, this will have higher risk of data loss and read delays on standby servers. If set to remote_apply, it will ensure immediate data availability at standby servers, but write performance may degrade since it should be applied on all/mentioned standby servers.
You can enable the archive mode if you’re planning to use continuous archiving and point-in-time recovery. While it’s not mandatory for streaming replication, enabling archive mode has extra benefits. If archive mode is not on, then we need to use the replication slots feature or ensure that wal_keep_segments value is set high enough based on load.
Refer to this excellent presentation to go into more details of high availability in PostgreSQL. In our next blog post, we’ll introduce you to the world of tools used to manage high availability for PostgreSQL using streaming replication.



