
AWS is the #1 cloud provider for open-source database hosting, and the go-to cloud for MySQL deployments. As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. While many AWS users default to their managed database solution, Amazon RDS, there are alternatives available that can improve your MySQL performance on AWS through advanced customization options and unlimited EC2 instance type support. ScaleGrid offers a compelling alternative to hosting MySQL on AWS that offers better performance, more control, and no cloud vendor lock-in and the same price as Amazon RDS. In this post, we compare the performance of MySQL Amazon RDS vs. MySQL Hosting at ScaleGrid on AWS High-Performance instances.
TLDR
ScaleGrid’s MySQL on AWS High-Performance deployment can provide 2x-3x the throughput at half the latency of Amazon RDS for MySQL with the added advantage of having 2 read replicas as compared to 1 in RDS.
MySQL on AWS Performance Test
| ScaleGrid | Amazon RDS | |
| Instance Type | AWS High Performance XLarge (see system details below) | DB Instance r4.xlarge (Multi-AZ) |
| Deployment Type | 3 Node Master-Slave Set with Semisynchronous Replication | Multi-AZ Deployment with 1 Read Replica |
| SSD Disk | Local SSD & General Purpose – 2TB | General Purpose – 2TB |
| Monthly Cost (USD) | $1,798 | $1,789 |
| Amazon RDS Costs | Price | Quantity | Total | Notes |
| Multi-AZ | ||||
| DB instance (hr) | $0.48 | 730 | $350.40 | db.r4.xlarge |
| DB instance (hr) | $0.48 | 730 | $350.40 | db.r4.xlarge |
| Storage (GB) | $0.115 | 2000 | $230.00 | General Purpose – 2TB (Single-AZ) |
| Read Replica | ||||
| DB instance (hr) | $0.48 | 730 | $350.40 | db.r4.xlarge (Single-AZ) |
| Storage (GB) | $0.115 | 2000 | $230.00 | General Purpose – 2TB (Single-AZ) |
| Other Costs | ||||
| Backup Storage (GB) | $0.095 | 1000 | $95.00 | Free up to 100% of DB storage |
| Data Transfer (out to Internet) | $0.09 | 0 | $0.00 | Free up to 1GB/mo |
| Data Transfer (out to regions) | $0.01 | 2000 | $20.00 | US East (N. Virginia) |
| Support | $162.62 | 1 | $162.62 | 10% of monthly cost |
| Total | $1,788.82 |
As you can see from the above table, MySQL RDS pricing is within $10 of ScaleGrid’s fully managed and all-inclusive MySQL hosting solution.
What are ScaleGrid’s High Performance Replica Sets?
caleGrid for MySQL High Performance replica set uses a hybrid of local SSD and EBS disk to achieve both high performance and high reliability. A typical configuration is deployed using a 3-node replica set:
- The Master and Slave-1 use local SSD disks.
- Slave-2 uses an EBS disk (can be a General Purpose or a Provisioned IOPS disk).

What does this mean? Since the Master and the Slave-1 are running on local SSD, you get the best possible disk performance from your AWS machines. No more network-based EBS, just blazing-fast local SSD. Reads and writes to your Primary, and even reads from Slave-1 will work at SSD speed. Slave-2 uses an EBS data disk, and you can configure the amount of IOPS required for your cluster. This configuration provides complete safety for your data, even in the event you lose the local SSD disks.
ScaleGrid’s MySQL AWS High Performance XLarge replica set uses i3.xlarge (30.5 GB RAM) instances with local SSD for the Master and Slave-1, and an i3.2xlarge (61 GB RAM) instance for Slave-2.
MySQL Configuration
A similar MySQL configuration is used on both ScaleGrid and RDS deployments:
| Configuration | Value |
| version | 5.7.25 community edition |
| innodb_buffer_pool_size | 25G |
| innodb_log_file_size | 1G |
| innodb_flush_log_at_trx_commit | 1 |
| sync_binlog | 1 |
| innodb_io_capacity | 3000 |
| innodb_io_capacity_max | 6000 |
| slave_parallel_workers | 30 |
| slave_parallel_type | LOGICAL_CLOCK |
MySQL Performance Benchmark Configuration
| Configuration | Details |
| Tool | Sysbench version 1.0.17 |
| Host | 1 r4.xlarge located in the same AWS data center as the Master MySQL |
| # Tables | 100 |
| # Rows per table | 5,000,000 |
| Workload generating script | oltp_read_write.lua |
MySQL Performance Test Scenarios and Results
To ensure we provide informative results for all MySQL AWS workload types, we have broken down our tests into these three scenarios so you can evaluate based on your read/write workload intensity:
- Read-Intensive Workload: 80% Reads and 20% Writes
- Balanced Workload: 50% Reads and 50% Writes
- Write-Intensive Workload: 20% Reads and 80% Writes
Each scenario is run with a varying number of sysbench client threads ranging from 50 to 400, and each test is run for 10 minutes. We measure throughput in terms of Queries Per Second (QPS) and 95th Percentile latency, and ensure that the max replication lag on the slaves does not cross 30sec. For some of the tests on the ScaleGrid deployment, MySQL configuration binlog_group_commit_sync_delay is tuned so that the slave replication lag does not go beyond 30sec. This technique is referred to as ‘slowing down the master to speed up the slaves’ and is explained in J-F Gagne’s blog.
Scenario-1: Read-Intensive Workload with 80% Reads and 20% Writes
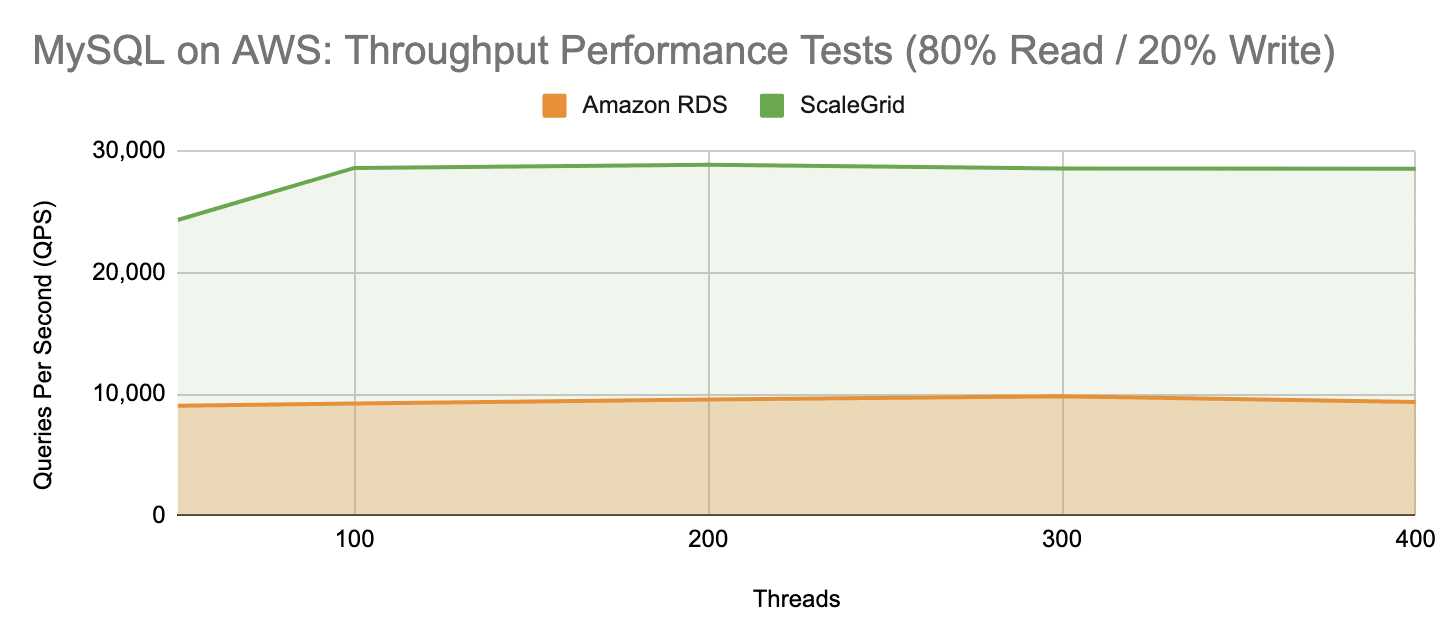
As we can see from the read-intensive workload tests, ScaleGrid high-performance MySQL instances on AWS can consistently handle around 27,800 QPS anywhere from 50 up to 400 threads. This is almost a 200% increase over MySQL RDS performance which averages only 9,411 QPS across the same range of threads.
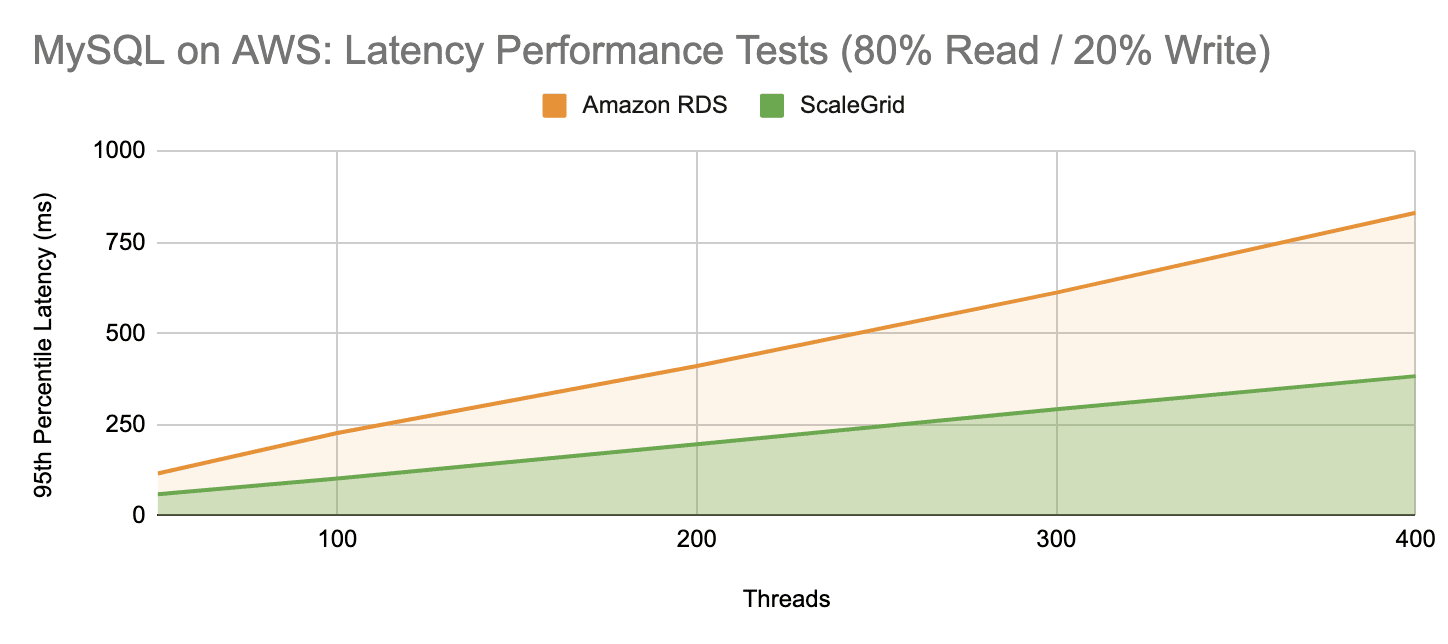
ScaleGrid also maintains 53% lower latency on average throughout the entire MySQL AWS performance tests. Both Amazon RDS and ScaleGrid latency increase steadily as the number of threads grows, where ScaleGrid maxes out at 383ms for 400 threads while Amazon RDS is at 831ms at the same level.
Scenario-2: Balanced Workload with 50% Reads and 50% Writes
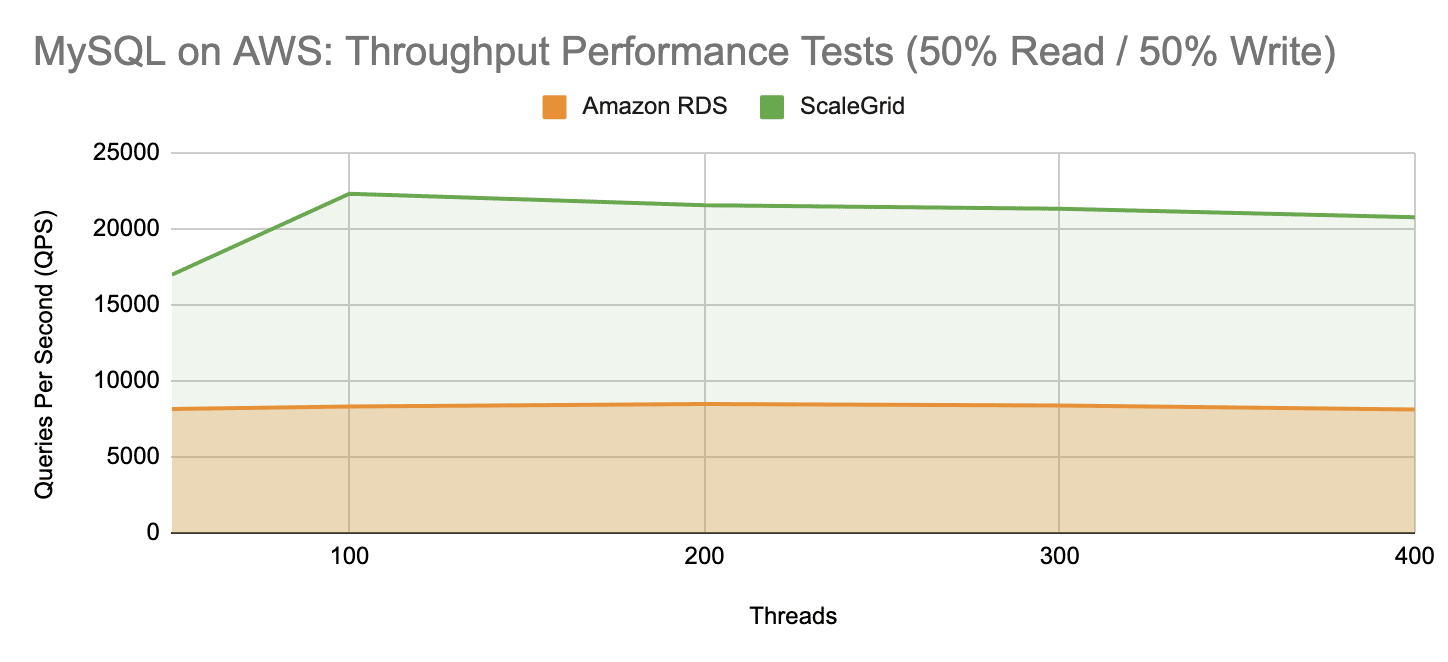
In our balanced workload performance tests, ScaleGrid’s MySQL High Performance deployment on AWS outperforms again with an average of 20,605 QPS on threads ranging from 50 to 400. Amazon RDS only averaged 8,296 for the same thread count, resulting in a 148% improvement with ScaleGrid.
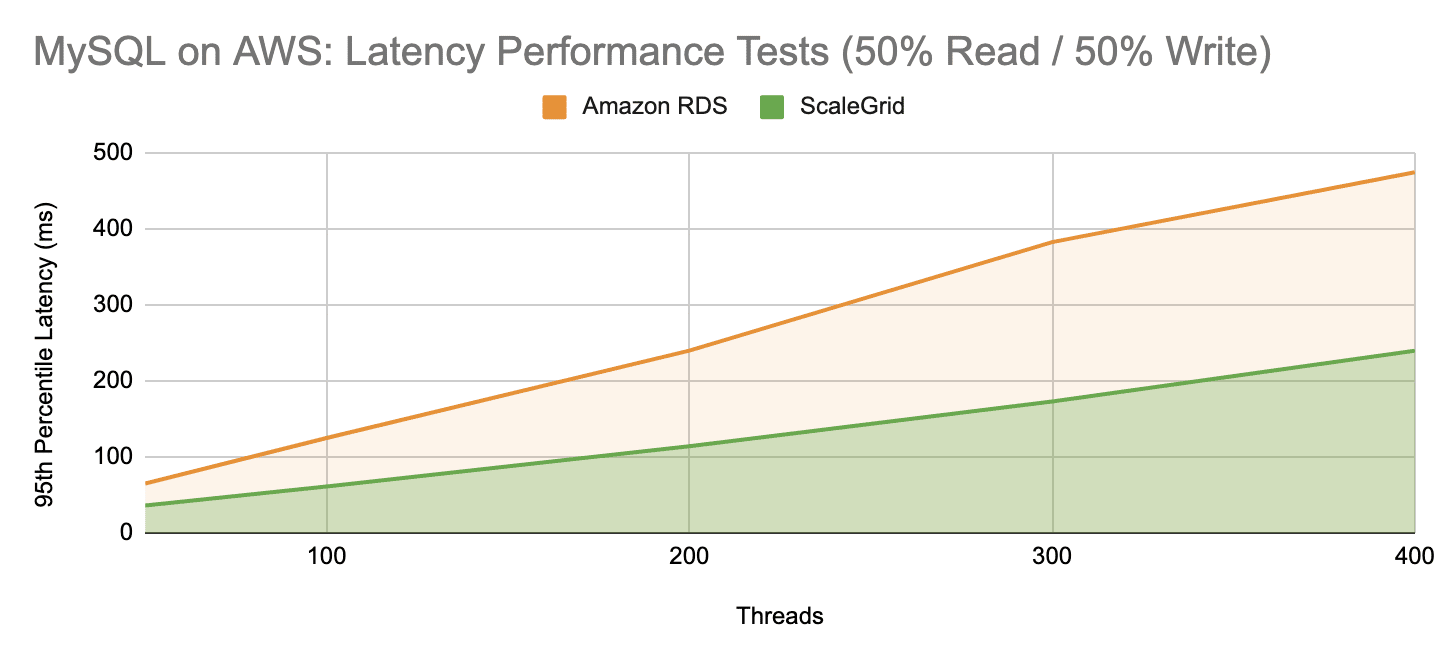
Both ScaleGrid and Amazon RDS latency significantly decreased in the balanced workload tests compared to the read-intensive tests covered above. Amazon RDS averaged 258ms latency in the balanced workload tests, whereas ScaleGrid only averaged 125ms achieving a 52% reduction in latency over MySQL on Amazon RDS.
Scenario-3: Write-Intensive Workload with 20% Reads and 80% Writes
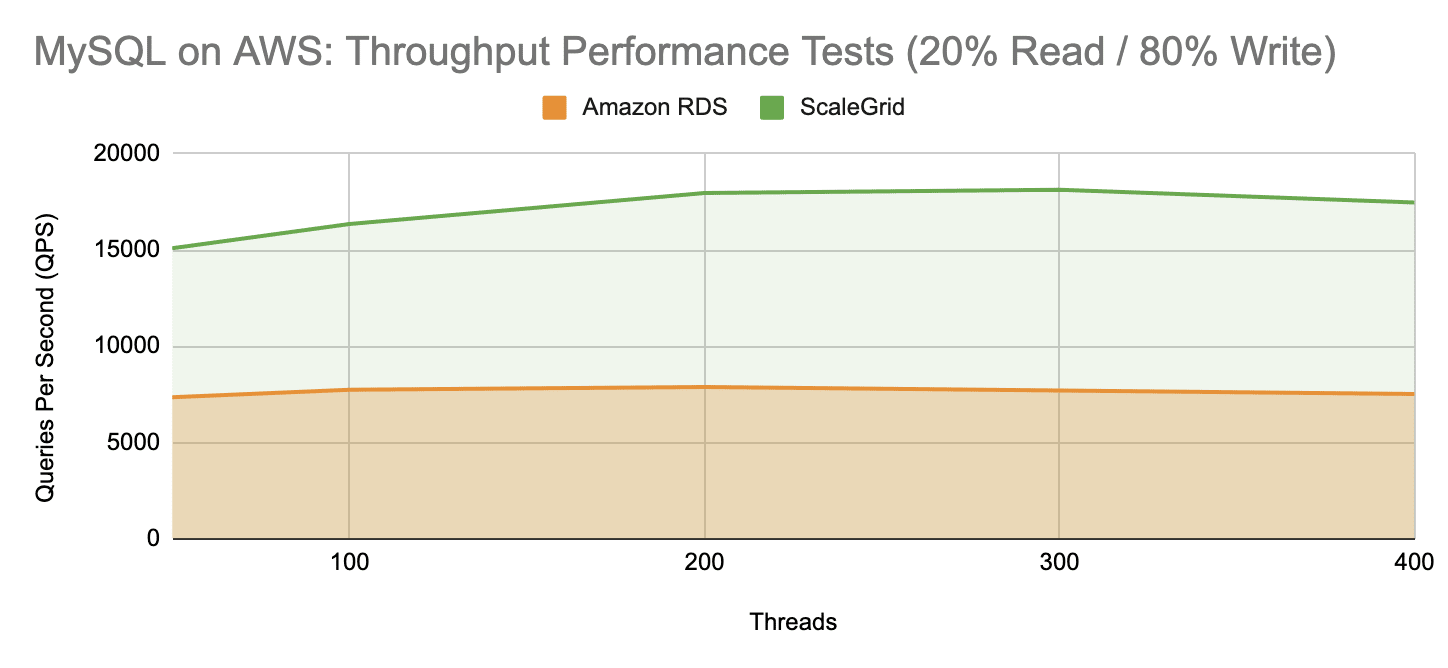
In our final write-intensive MySQL AWS workload scenario, ScaleGrid achieved significantly higher throughput performance with an average of 17,007 QPS over the range of 50 to 400 threads. This is a 123% improvement over Amazon RDS which only achieved 7,638 QPS over the same number of threads.
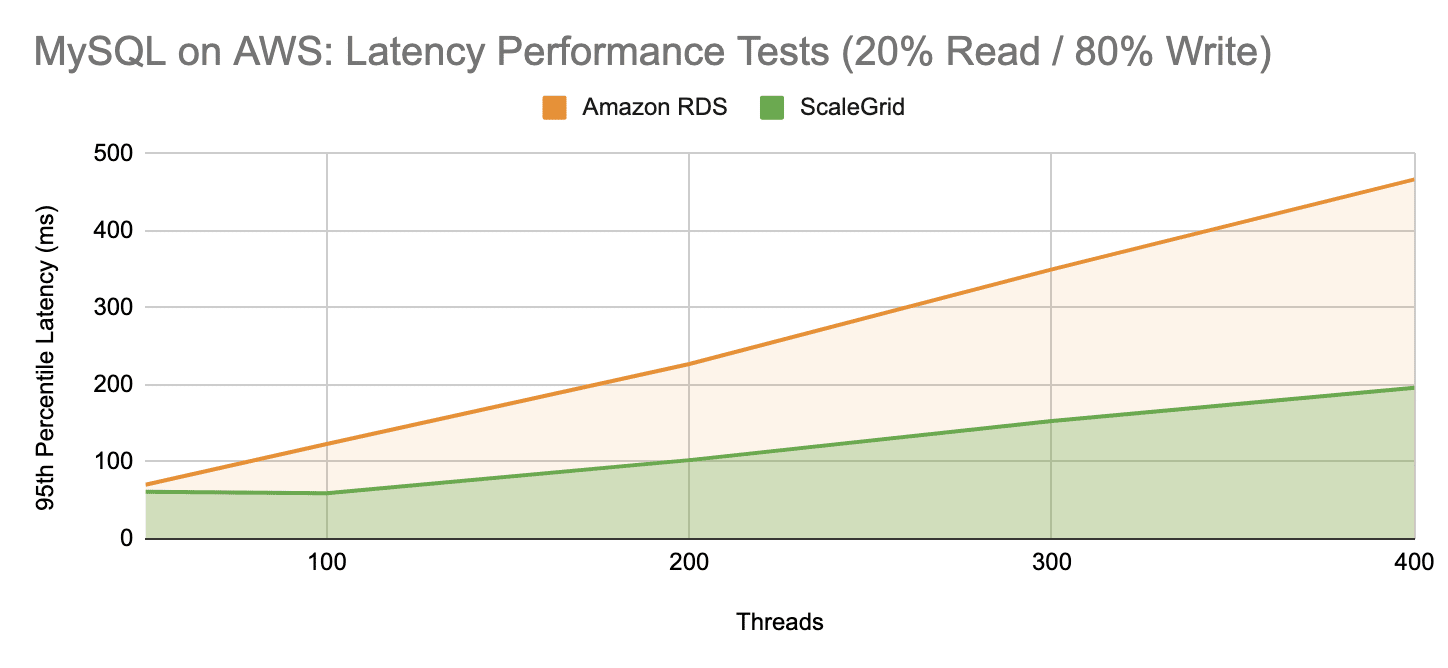
The 95th percentile latency tests also produced significantly lower latency for ScaleGrid at an average of 114ms over 50 to 400 threads. Amazon RDS achieved an average of 247ms in their latency tests, resulting in a 54% average reduction in latency when deploying ScaleGrid’s High Performance MySQL on AWS services over Amazon RDS.
Analysis
As we observed from the test results, read-intensive workloads resulted in both higher throughput and latency over balanced workloads and write-intensive workloads, regardless of how MySQL was deployed on AWS:
| MySQL on AWS Throughput Performance Test Averages | ScaleGrid | Amazon RDS | ScaleGrid Improvement |
| Read-Intensive Throughput | 27,795 | 9,411 | 195.4% |
| Balance Workload Throughput | 20,605 | 8,296 | 148.4% |
| Write-Intensive Throughput | 17,007 | 7,638 | 122.7% |
| MySQL on AWS Latency Performance Test Averages | ScaleGrid | Amazon RDS | ScaleGrid Improvement |
| Read-Intensive Latency | 206ms | 439ms | -53.0% |
| Balanced Workload Latency | 125ms | 258ms | -51.6% |
| Write-Intensive Latency | 114ms | 247ms | -53.8% |
Explanation of Results
- We see that the ScaleGrid MySQL on AWS deployment provided close to 3x better throughput for the read-intensive workload compared to the RDS deployment.
- As the write load increased, though the absolute throughput decreased, ScaleGrid still provided close to 2.5x better throughput performance.
- For write-intensive workloads, we found that the replication lag started kicking in for the EBS slave on the ScaleGrid deployment. Since our objective was to keep the slave replication lag within 30sec for our runs, we introduced binlog_group_commit_sync_delay to ensure that the slave could achieve better parallel execution. This controlled the delay and resulted in lesser absolute throughput on the ScaleGrid deployment, but we could still see a 2.2x better throughput compared to RDS deployment.
- For all of the read-intensive, write-intensive, and balanced workload scenarios, ScaleGrid offered 0.5X lower latency characteristics compared to RDS.
ScaleGrid’s ‘High Performance’ deployment can provide 2x-3x the throughput at half the latency of RDS with the added advantage of having 2 read replicas as compared to 1 in RDS. To learn more about ScaleGrid’s MySQL hosting advantages over Amazon RDS for MySQL, check out our Compare MySQL Providers page or start a free 7-day trial to explore the fully managed DBaaS platform.



