In this post, we’ll show you how to use MongoDB connection pooling on AWS Lambda using both Node.js and Java drivers.
What is AWS Lambda?
AWS Lambda is an event-driven, serverless computing service provided by Amazon Web Services. It allows a user to run code without any of the administrative tasks, unlike that of EC2 instances where a user is responsible for provisioning servers, scaling, high availability, etc. Instead, you only have to upload the code and set up the event trigger, and AWS Lambda automatically takes care of everything else.
AWS Lambda supports various runtimes, including Node.js, Python, Java, and Go. It can be directly triggered by AWS services like S3, DynamoDB, Kinesis, SNS, etc. In our example, we use the AWS API gateway to trigger the Lambda functions.
What is a Connection Pool?
Opening and closing a database connection is an expensive operation since it involves both CPU time and memory. If an application needs to open a database connection for every operation, then that will have a severe performance impact.
What if we have a bunch of database connections that are kept alive in a cache? Whenever an application needs to perform a database operation, it can borrow a connection from the cache, perform the required operation, and give it back. By using this approach, we can save the time required for establishing a new connection every time and reuse the connections. This cache is known as the connection pool.
The size of the connection pool is configurable in most of the MongoDB drivers, and the default pool size varies from driver to driver. For example, it’s 5 in Node.js driver, whereas it’s 100 in Java driver. The connection pool size determines the maximum number of parallel requests which your driver can handle at a given time. If the connection pool limit is reached, any new requests will be made to wait until the existing ones are completed. Hence, the pool size needs to be chosen carefully, considering the application load and concurrency to be achieved.
MongoDB Connection Pools in AWS Lambda
In this post, we’ll show you examples involving both Node.js and Java driver for MongoDB. For this tutorial, we use MongoDB hosted on ScaleGrid using AWS EC2 instances. It takes less than 5 minutes to set up, and you can create a free 30-day trial here to get started.
Java Driver MongoDB Connection Pool
Here’s the code to enable the MongoDB connection pool using the Java driver in AWS Lambda handler function:
public class LambdaFunctionHandler
implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
private MongoClient sgMongoClient;
private String sgMongoClusterURI;
private String sgMongoDbName;
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input, Context context) {
APIGatewayProxyResponseEvent response = new APIGatewayProxyResponseEvent();
response.setStatusCode(200);
try {
context.getLogger().log("Input: " + new Gson().toJson(input));
init(context);
String body = getLastAlert(input, context);
context.getLogger().log("Result body: " + body);
response.setBody(body);
} catch (Exception e) {
response.setBody(e.getLocalizedMessage());
response.setStatusCode(500);
}
return response;
}
private MongoDatabase getDbConnection(String dbName, Context context) {
if (sgMongoClient == null) {
context.getLogger().log("Initializing new connection");
MongoClientOptions.Builder destDboptions = MongoClientOptions.builder();
destDboptions.socketKeepAlive(true);
sgMongoClient = new MongoClient(new MongoClientURI(sgMongoClusterURI, destDboptions));
return sgMongoClient.getDatabase(dbName);
}
context.getLogger().log("Reusing existing connection");
return sgMongoClient.getDatabase(dbName);
}
private String getLastAlert(APIGatewayProxyRequestEvent input, Context context) {
String userId = input.getPathParameters().get("userId");
MongoDatabase db = getDbConnection(sgMongoDbName, context);
MongoCollection coll = db.getCollection("useralerts");
Bson query = new Document("userId", Integer.parseInt(userId));
Object result = coll.find(query).sort(Sorts.descending("$natural")).limit(1).first();
context.getLogger().log("Result: " + result);
return new Gson().toJson(result);
}
private void init(Context context) {
sgMongoClusterURI = System.getenv("SCALEGRID_MONGO_CLUSTER_URI");
sgMongoDbName = System.getenv("SCALEGRID_MONGO_DB_NAME");
}
}
The connection pooling is achieved here by declaring a sgMongoClient variable outside of the handler function. The variables declared outside of the handler method remain initialized across calls, as long as the same container is reused. This is true for any other programming language supported by AWS Lambda.
Node.js Driver MongoDB Connection Pool
For the Node.js driver, declaring the connection variable in global scope will also do the trick. However, there is a special setting without which the connection pooling is not possible. That parameter is callbackWaitsForEmptyEventLoop which belongs to Lambda’s context object. Setting this property to false will make AWS Lambda freeze the process and any state data. This is done soon after the callback is called, even if there are events in the event loop.
Here’s the code to enable the MongoDB connection pool using the Node.js driver in AWS Lambda handler function:
'use strict'
var MongoClient = require('mongodb').MongoClient;
let mongoDbConnectionPool = null;
let scalegridMongoURI = null;
let scalegridMongoDbName = null;
exports.handler = (event, context, callback) => {
console.log('Received event:', JSON.stringify(event));
console.log('remaining time =', context.getRemainingTimeInMillis());
console.log('functionName =', context.functionName);
console.log('AWSrequestID =', context.awsRequestId);
console.log('logGroupName =', context.logGroupName);
console.log('logStreamName =', context.logStreamName);
console.log('clientContext =', context.clientContext);
// This freezes node event loop when callback is invoked
context.callbackWaitsForEmptyEventLoop = false;
var mongoURIFromEnv = process.env['SCALEGRID_MONGO_CLUSTER_URI'];
var mongoDbNameFromEnv = process.env['SCALEGRID_MONGO_DB_NAME'];
if(!scalegridMongoURI) {
if(mongoURIFromEnv){
scalegridMongoURI = mongoURIFromEnv;
} else {
var errMsg = 'Scalegrid MongoDB cluster URI is not specified.';
console.log(errMsg);
var errResponse = prepareResponse(null, errMsg);
return callback(errResponse);
}
}
if(!scalegridMongoDbName) {
if(mongoDbNameFromEnv) {
scalegridMongoDbName = mongoDbNameFromEnv;
} else {
var errMsg = 'Scalegrid MongoDB name not specified.';
console.log(errMsg);
var errResponse = prepareResponse(null, errMsg);
return callback(errResponse);
}
}
handleEvent(event, context, callback);
};
function getMongoDbConnection(uri) {
if (mongoDbConnectionPool && mongoDbConnectionPool.isConnected(scalegridMongoDbName)) {
console.log('Reusing the connection from pool');
return Promise.resolve(mongoDbConnectionPool.db(scalegridMongoDbName));
}
console.log('Init the new connection pool');
return MongoClient.connect(uri, { poolSize: 10 })
.then(dbConnPool => {
mongoDbConnectionPool = dbConnPool;
return mongoDbConnectionPool.db(scalegridMongoDbName);
});
}
function handleEvent(event, context, callback) {
getMongoDbConnection(scalegridMongoURI)
.then(dbConn => {
console.log('retrieving userId from event.pathParameters');
var userId = event.pathParameters.userId;
getAlertForUser(dbConn, userId, context);
})
.then(response => {
console.log('getAlertForUser response: ', response);
callback(null, response);
})
.catch(err => {
console.log('=> an error occurred: ', err);
callback(prepareResponse(null, err));
});
}
function getAlertForUser(dbConn, userId, context) {
return dbConn.collection('useralerts').find({'userId': userId}).sort({$natural:1}).limit(1)
.toArray()
.then(docs => { return prepareResponse(docs, null);})
.catch(err => { return prepareResponse(null, err); });
}
function prepareResponse(result, err) {
if(err) {
return { statusCode:500, body: err };
} else {
return { statusCode:200, body: result };
}
}
AWS Lambda Connection Pool Analysis and Observations
To verify the performance and optimization of using connection pools, we ran few tests for both Java and Node.js Lambda functions. Using the AWS API gateway as a trigger, we invoked the functions in a burst of 50 requests per iteration and determined the average response time for a request in each iteration. This test was repeated for Lambda functions without using the connection pool initially, and later with the connection pool.
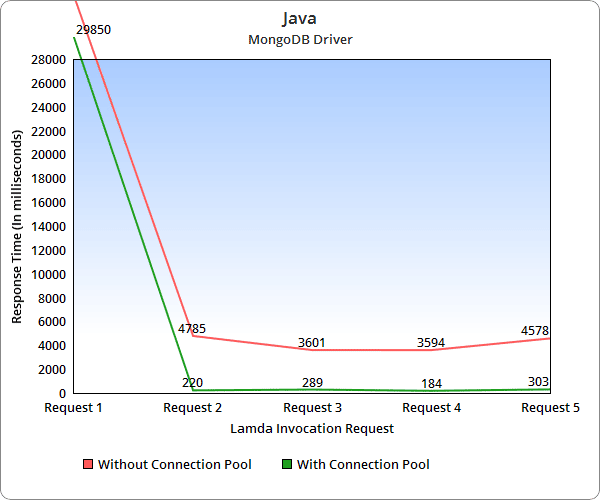
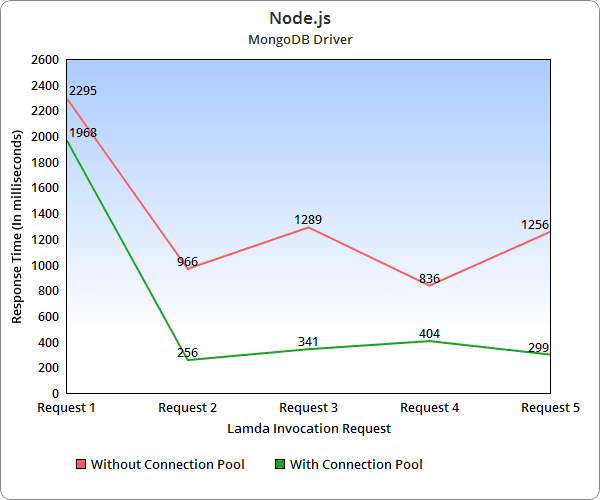
The graphs above represent the average response time of a request in each iteration. You can see here the difference in response time when a connection pool is used for performing database operations. The response time using a connection pool is significantly lower due to the fact that the connection pool initializes once and reuses the connection instead of opening and closing the connection for each database operation.
The only notable difference between Java and Node.js Lambda functions is the cold start time.
What is Cold Start Time?
Cold start time refers to the time taken by the AWS Lambda function for initialization. When the Lambda function receives its first request, it will initialize the container and the required process environment. In the above graphs, the response time of request 1 includes the cold start time, which significantly differs based on the programming language used for AWS Lambda function.
Do I Need to Worry About Cold Start Time?
If you’re using the AWS API gateway as a trigger for the Lambda function, then you must take cold start time into consideration. The API gateway response will error out if the AWS Lambda integration function isn’t initialized in the given time range. The API gateway integration timeout ranges from 50 milliseconds to 29 seconds.
In the graph for the Java AWS Lambda function, you can see that the first request took more than 29 seconds, hence, the API gateway response errored out. Cold start time for AWS Lambda function written using Java is higher compared to other supported programming languages. In order to address these cold start time issues, you can fire an initialization request before the actual invocation. The other alternative is to have a retry on the client side. That way, if the request fails due to cold start time, the retry will succeed.
What Happens to AWS Lambda Function During Inactivity?
In our testing, we also observed that AWS Lambda hosting containers were stopped when they were inactive for a while. This interval varied from 7 to 20 minutes. So, if your Lambda functions are not used frequently, then you need to consider keeping them alive by either firing heartbeat requests or adding retries on the client side.
What Happens When I Invoke Lambda Functions Concurrently?
If Lambda functions are invoked concurrently, then Lambda will use many containers to serve the request. By default, AWS Lambda provides unreserved concurrency of 1000 requests and is configurable for a given Lambda function.
This is where you need to be careful about the connection pool size since concurrent requests can open too many connections. So, you must keep the connection pool size optimal for your function. However, once the containers are stopped, connections will be released based on timeout from the MongoDB server.
AWS Lambda Connection Pooling Conclusion
Lambda functions are stateless and asynchronous, and by using the database connection pool, you will be able to add a state to it. However, this will only help when the containers are reused, allowing you to save a lot of time. Connection pooling using AWS EC2 is easier to manage because a single instance can track the state of its connection pool without any issue. Thus, using AWS EC2 significantly reduces the risk of running out of database connections. AWS Lambda is designed to work better when it can just hit an API and doesn’t have to connect to a database engine.



