Grasping the concept of Redis sharding is essential for expanding your Redis database. This method involves splitting data over various nodes to improve the database’s efficiency. In this article, we will explain Redis sharding, explore its pros and cons, and how to apply it.
Key Takeaways
- Redis sharding is a method of splitting the keyspace into 16384 hash slots for distribution across nodes. It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot.
- Redis Cluster is Redis’s native sharding solution. It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance.
- ScaleGrid offers managed DBaaS solutions to simplify scaling and managing Redis deployments with features such as dynamic scaling with minimal downtime, automated backups, and high availability, suitable for cloud platforms like AWS, Azure, and Google Cloud.
Redis Sharding: An Overview

Consider Redis Cluster as a multi-lane highway where the lanes represent hash slots, and traffic symbolizes data. Similar to how each lane on the highway handles certain vehicles for more efficient travel, in Redis sharding, different nodes manage various pieces of data through consistent hashing. The purpose is to scale out distributed systems effectively and offer improved management and performance while processing numerous keys. Specifically, 16384 hash slots make up the entire keyspace within Redis. These are allocated across multiple Redis cluster nodes.
Redis isn’t alone in utilizing sharding strategies. It’s a common concept found throughout database technologies to distribute workload efficiently. Yet what distinguishes Redis is its internal handling of shards within clusters. Each shard essentially operates as an independent instance of Redis that carries a portion of your dataset. A single cluster enhances redundancy and scalability by incorporating several such shards into its structure by spreading stored information among various nodes.
What is Redis Sharding?
Sharding in Redis involves dividing data across multiple machines to enhance scalability and maintain availability. Consider this scenario: if a single machine or Redis instance were to fail, only its respective shard would be affected. The rest of the shards would continue functioning as normal, thus minimizing downtime and maintaining a stable user experience.
Sharding can handle sudden spikes in traffic by spreading out and scaling the workload over various machines. Unlike replication, which merely copies data from one place to another, sharding entails horizontally partitioning the database into separate segments or shards placed on different servers.
How Does Redis Sharding Work?
While Redis sharding may not be considered magical, it is a remarkable engineering feat. The key distribution mechanism across nodes in a Redis cluster hinges on dividing the entire keyspace into 16,384 hash slots. To ascertain which specific hash slot a given key belongs to, there’s an established formula: the CRC16 of the key modulo 16384 determines its assigned hash slot value for use in the hashing process.
The clever aspect of sharding manifests when utilizing hashtags within keys. These ensure that related keys are mapped to the same hash slot and consequently housed on the same node within the cluster. This is particularly important for multi-key operations, as it ensures that multiple keys are allocated in the same hash slot, facilitating efficient data management and access. In a common configuration involving a three-node Redis Cluster, each node is responsible for approximately one-third of all available slots as per shard limit guidelines, with an even distribution among them ensuring efficient data management and access.
Advantages and Limitations of Redis Sharding
Understanding the pros and cons of Redis sharding is crucial for making educated choices on its deployment. Like all technologies, it has distinct benefits and constraints, such as the need to manage hash slot distribution within a particular node, that should be considered before implementation.
Advantages
Redis sharding efficiently spreads the workload across multiple database hosts, which mitigates the limitations of a single server and enhances overall performance. Visualize it as a relay race. Instead of one runner (server) bearing the entire burden until exhaustion, several runners (servers) take turns, which leads to enhanced efficiency.
The architecture behind Redis Cluster offers high availability through its cluster nodes, essential for continuous operation in distributed environments. With Redis Enterprise backing this system, users can access diverse configurations ranging from 90 shards without replicas down to 15 shards accompanied by five replicas each. This adaptability allows for a careful balance between availability and efficient resource utilization while leveraging a Redis server within each cluster node and maintaining peak performance and dependability.
While Redis sharding efficiently distributes data across nodes, Redis’s role in AI infrastructure is equally critical. Its use in powering real-time predictions, chatbot optimization, and vector search demonstrates how Redis supports advanced AI workloads. Explore these Redis-powered AI applications to see how it supports performance at scale beyond traditional caching and storage.
Limitations
Sharding in Redis brings several advantages, but it also introduces certain constraints. A significant hurdle is the necessity for specialized client support. This means adjustments must be made on the client side to work harmoniously with a sharded setup.
Multi-key operations within a Redis Cluster are only feasible when all keys implicated fall within an identical hash slot. Trying to conduct operations spanning various hash slots will provoke a CROSSSLOT error message. In contrast to single-node Redis setups that can accommodate numerous databases, a Redis Cluster confines users strictly to one database (database 0), which may constrain particular scenarios.
Redis Cluster: The Native Sharding Solution

The entire keyspace in Redis Clusters is divided into 16384 slots (called hash slots), and these slots are assigned to multiple Redis nodes. A given key is mapped to one of these slots, and the hash slot for a key is computed as:
HASH_SLOT = CRC16(key) mod 16384
Multi-key operations are supported on Redis Clusters as long as all the keys involved in a single command execution belong to the same hash slot. This can be ensured using hash tags.
The Redis Cluster Specification is the definitive guide to understanding the technology’s internals, while the Redis Cluster Tutorial provides deployment and administration guidelines.
When Should You Deploy a Redis Cluster?
If you need a sharded Redis solution, the Redis Cluster solution can be a good fit. Redis Cluster is a native solution that is simple and offers great performance.
Typically, people start looking at sharding their Redis deployments when they’ve started to saturate a standalone Redis node with writes and want to spread writes out to multiple nodes. Even though Redis is primarily single-threaded, I/O typically becomes network- or memory-bound on a standalone basis before it can start saturating the CPU. Memory bound can be overcome to an extent by adding more memory to a standalone system, but it starts to become prohibitive in terms of cost, backup, restart, warm-up times, etc., beyond a certain point.
On the other hand, if you’re looking only to spread your read across multiple nodes, it’s much easier to add read replicas to the standalone.
Compared to other sharding solutions for Redis, shard rebalancing in Redis Clusters is transparent to applications. This makes adding or removing shards very easy without affecting the application.
Redis Cluster serves as an intrinsic sharding mechanism that functions in cluster mode, delivering several advantages such as:
- Distributing write operations among various Redis cluster nodes
- Ensuring a scalable, high-performance solution with enhanced availability for data management
- Enabling the perks of sharding natively without dependency on supplementary tools or utilities.
Redis Cluster Features
Redis Cluster ensures horizontal scalability by automatically partitioning data across multiple servers, thus dividing them into numerous shards. This approach guarantees that Redis Cluster can scale alongside your increasing volume of data while maintaining steady performance.
Redis Cluster utilizes master-replica setups to enhance availability and offers smooth transitions if a master goes down by promoting one of its replicas. You can be confident that with Redis Cluster, your data remains accessible even during system failures.
Redis Cluster Configuration and Cluster Nodes
Certain key configuration parameters must be considered when establishing a Redis cluster incorporating multiple Redis nodes. Each node within the cluster must maintain two active TCP connections: one for processing the standard Redis commands and another dedicated to inter-node cluster bus communication. These ports must be accessible to support vital clustering operations such as detecting node failures, disseminating configuration updates, and executing failover processes when an individual node encounters issues.
Data distribution across master nodes within a cluster is structured by evenly dividing hash slots amongst all masters present in the system. This ensures an equitable allocation of total available hash slots per master. As additional master nodes join the group of existing ones, they receive newly designated ranges of these hash slots. This strategic assignment facilitates both a balanced workload spread across different masters and efficient data management throughout various points in your Redis Cluster network.
Here are some of our other posts in the Redis data structures series:
Connecting to a Redis Cluster with Popular Clients

If you choose to deploy a Redis™ Cluster with ScaleGrid, you get a fully featured Redis Cluster deployment compatible with the standard release.
If you’re just starting, sign up for a free 7-day trial on the ScaleGrid console, and check out this documentation on creating your first ScaleGrid for Redis™ deployment.
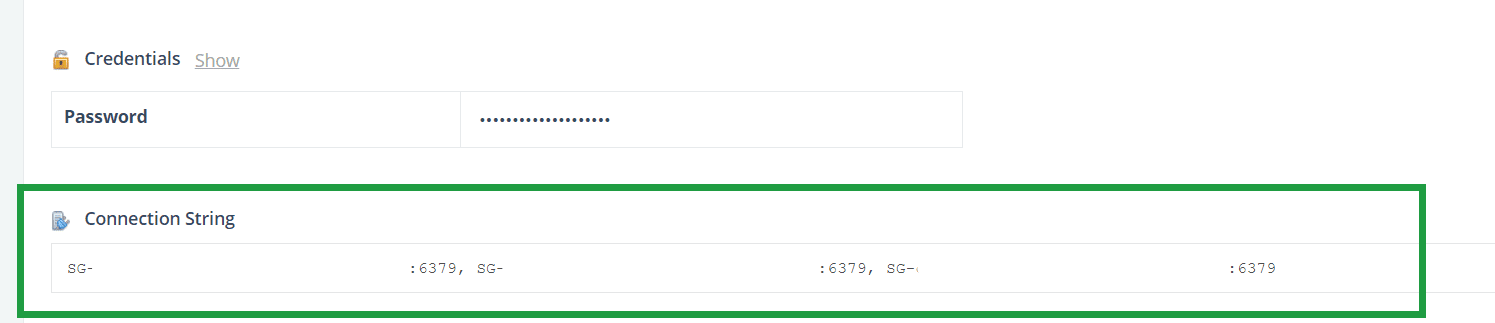
Here’s what you need to connect to the Redis™ Cluster at ScaleGrid:
- List of node names
- Ports
- Authentication string
The Overview tab of your Redis™ deployment details page has the list of masters of each shard, along with port numbers and authentication information:
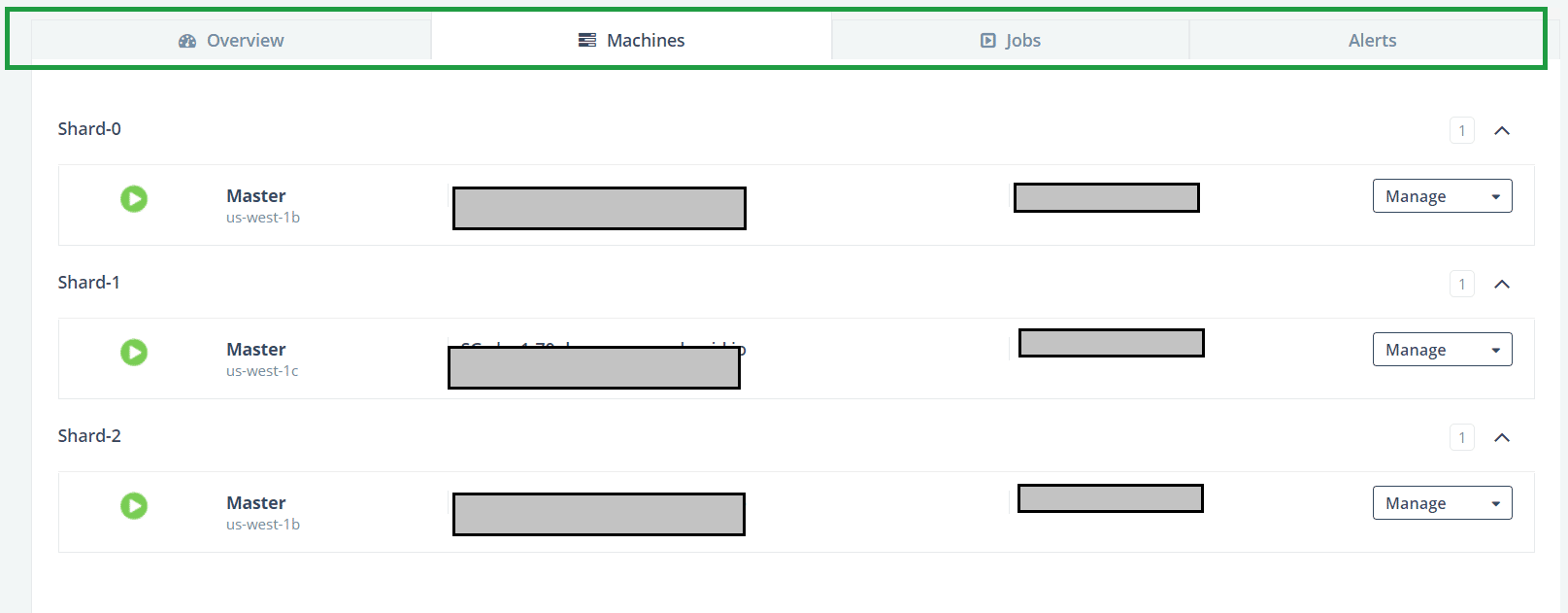
Alternatively, the list of all the nodes of the cluster is available on the Machines tab:
Connecting With Java
Among the popular Redis Java clients, Jedis and Lettuce support Redis™ Clusters. We will take Jedis as our example.
Redis™ Cluster connections are abstracted by the JedisCluster class. The best examples of using this class to connect to Redis™ Clusters can be found in the Jedis tests and Jedis source code. Unfortunately, when authentication is specified, the JedisCluster constructor is not very clean at this time. Here’s an example that writes 100 keys to the Redis™ Cluster. Note that since the keys aren’t tagged, they will end up in different slots on different nodes:
...
import java.util.HashSet;
import java.util.Set;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
...
public class RedisClusterModeTest {
public static final int DEFAULT_TIMEOUT = 5000;
public static final int DEFAULT_REDIRECTIONS = 5;
public static void main(String[] args) {
Set jedisClusterNodes = new HashSet();
jedisClusterNodes.add(new HostAndPort("SG-example-1.servers.scalegridiostg.wpengine.com, 6379));
jedisClusterNodes.add(new HostAndPort("SG-example-2.servers.scalegridiostg.wpengine.com", 6379));
jedisClusterNodes.add(new HostAndPort("SG-example-3.servers.scalegridiostg.wpengine.com", 6379));
jedisClusterNodes.add(new HostAndPort("SG-example-4.servers.scalegridiostg.wpengine.com", 6379));
jedisClusterNodes.add(new HostAndPort("SG-example-5.servers.scalegridiostg.wpengine.com", 6379));
jedisClusterNodes.add(new HostAndPort("SG-example-6.servers.scalegridiostg.wpengine.com", 6379));
JedisCluster jedis = new JedisCluster(jedisClusterNodes, DEFAULT_TIMEOUT, DEFAULT_TIMEOUT, DEFAULT_REDIRECTIONS, <auth>, new JedisPoolConfig());
for (int i = 0; i < 100; i++) {
jedis.set("key" + i, "value" + i);
}
jedis.close();
}
}The arguments to the constructor are documented in the Jedis API docs. We recommend that you specify all the nodes of the cluster during cluster creation with Jedis.
Connecting With Ruby
The most popular Redis client in Ruby is redis-rb. It also supports Redis™ Clusters so we’ll use it in our example.
Redis-rb
redis-rb versions 4.1.0 and above have support for Redis™ Clusters. The ‘cluster’ option needs to be specified during connection initialization, and you can refer to this documentation for exact semantics. Here’s the same program as the Java example above in Ruby:
require 'redis'
require 'pp'
NODES = ["redis://SG-example-1.servers.scalegridiostg.wpengine.com:6379",
"redis://SG-example-2.servers.scalegridiostg.wpengine.com:6379",
"redis://SG-example-3.servers.scalegridiostg.wpengine.com:6379",
"redis://SG-example-4.servers.scalegridiostg.wpengine.com:6379",
"redis://SG-example-5.servers.scalegridiostg.wpengine.com:6379",
"redis://SG-example-6.servers.scalegridiostg.wpengine.com:6379"]
begin
pp "Attempting connection..."
redis = Redis.new(cluster: NODES, password: <auth>)
100.times { |i| redis.set("key#{i}", "value#{i}") }
pp "Done..."
redis.close
rescue StandardError => e
puts e.message
endConnecting With Node.js
Node_redis is the most popular Redis client in Node.js. However, it doesn’t officially support Redis™ Clusters yet. ioredis is another popular Redis client which has Redis™ Clusters support so we’ll use this for our Node.js example.
ioredis
The ioredis documentation describes the details of the additional parameters that must be passed for connecting to Redis™ Clusters, and a basic example is also provided in the README. Here’s an example program that prompts the user for a key and read its value from the Redis™ Cluster:
const readline = require('readline');
const Redis = require('ioredis');
var cluster = new Redis.Cluster([{
port: 6379,
host: 'SG-example-1.servers.scalegridiostg.wpengine.com'
},
{
port: 6379,
host: 'SG-example-2.servers.scalegridiostg.wpengine.com'
},
{
port: 6379,
host: 'SG-example-3.servers.scalegridiostg.wpengine.com'
},
{
port: 6379,
host: 'SG-example-4.servers.scalegridiostg.wpengine.com'
},
{
port: 6379,
host: 'SG-example-5.servers.scalegridiostg.wpengine.com'
},
{
port: 6379,
host: 'SG-example-6.servers.scalegridiostg.wpengine.com'
}
], { redisOptions: { password: '<auth>' } });
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
prompt: 'enter key> '
});
console.log('Welcome to the Redis Cluster reader. Enter the key which you want to read [Ctrl D to Exit]');
rl.prompt();
rl.on('line', (line) => {
if (line.trim()) {
cluster.get(line, function (err, result) {
if (err) {
console.error(err);
} else {
console.log("value: " + result);
}
rl.prompt();
});
} else {
console.error("No input received");
rl.prompt();
}
}).on('close', () => {
console.log('\nterminating');
cluster.quit();
process.exit(0);
});After installing the most recent versions of the Redis drivers on your client machines, you should be able to execute any of these examples.
Scaling Your Redis Deployment with ScaleGrid
As the volume and complexity of data expand, it becomes increasingly difficult to manage and scale Redis deployments efficiently. Enter ScaleGrid, a managed Database-as-a-Service (DBaaS) provider that eases these challenges by offering features tailored to enhance the scaling process for Redis. These capabilities include dynamic scaling with reduced downtime, automated backups paired with point-in-time recovery options, robust high availability supported by automatic failover mechanisms, comprehensive monitoring and alerti ng systems as well as stringent security protocols coupled with compliance adherence.
Leveraging ScaleGrid allows you to concentrate on your primary business operations while entrusting the efficiency and dependability of your Redis data management needs to expert handling. With this solution in place, maintaining effective performance of your Redis deployments doesn’t have to be a concern anymore.
Benefits of ScaleGrid
ScaleGrid delivers comprehensive management for Redis hosting, allowing companies to leverage multiple cloud services such as AWS, Azure, Digital Ocean, and Google Cloud Platform.
This service removes the burden of manual database configuration, upkeep, and intricate scaling activities from users’ shoulders. Thus, it enables them to focus their efforts on innovation and essential business operations.
Leveraging ScaleGrid for database administration can enhance performance, bolster security measures, and amplify scalability, paving the way for possible expansion. Clients who run ScaleGrid through their personal AWS accounts retain control over their instances with SSH access privileges intact.
Getting Started with ScaleGrid
Initiating your experience with ScaleGrid can be done effortlessly by setting up a trial account through the ScaleGrid Console, where you select the type of database hosting desired.
When it’s time to expand your Redis cluster, simply sign in to the ScaleGrid console and go over to your cluster’s detail page. Here you’ll find an option named ‘Scale Up’, which allows you to choose a more substantial instance size for scaling easily. This functionality that ScaleGrid offers simplifies scaling Redis deployments by eliminating complicated manual configurations and ongoing management tasks.
Best Practices for Redis Sharding
Possessing a thorough grasp of sharding in Redis and the methods for scaling it through ScaleGrid, we can now explore key recommendations to enhance your Redis deployments. Adhering to these best practices will maximize your Redis clusters’ efficiency.
Data Structure Design
Optimizing Redis sharding relies heavily on the effective creation of data structures. One should employ Redis’ native data types, such as strings, lists, sets, and hashes, in a manner that suits their requirements. Constructing efficient keys within Redis is crucial. Adopting naming conventions like objectType:objectId:field can greatly enhance the maintainability and comprehension of your database.
Implementing expirations for key values is essential to managing memory usage within Redis effectively. This practice is especially important for keys that do not need to persist indefinitely. Although Redis does not offer built-in namespaces directly out-of-the-box, utilizing colons in key names allows users to mimic namespace functionality, which proves extremely useful in environments with multiple tenants or diverse, distinct datasets.
Monitoring and Maintenance
The content does not specifically address the methods for monitoring or upkeep of a sharded Redis setup. It briefly mentions the resharding procedure. To remove a master node from a Redis Cluster correctly, you must first ensure that this node has no data stored on it (ensuring it’s an empty node). If not empty, transfer the data to another node through resharding or conduct a manual failover before its removal.
Redis Cluster effectively scales your data, increasing scalability and accessibility by dispersing it across several nodes. This native sharding feature ensures top performance and reliability within a Redis environment. Various clients, such as Java with Jedis, Ruby with redis-rb, and Node.js with ioredis, facilitate seamless connection to the cluster. ScaleGrid offers managed DBaaS solutions that make expanding your Redis deployments more straightforward. By carefully designing your data structures and maintaining diligent monitoring, you can maximize the efficiency of your Redis sharding to enhance overall deployment outcomes.
If you’re ready to migrate your Redis deployments to ScaleGrid’s fully managed platform for Redis™, check out the amazing features available on the ScaleGrid console through a free 7-day trial. Our AWS hosting for Redis™ plans is available across 14 different data centers worldwide, and we’re the only service for Redis™ that allows you to manage your deployments within your cloud account.
Frequently Asked Questions
What is Redis sharding?
Sharding in Redis is a strategy utilized to enhance scalability and availability by distributing data efficiently across multiple nodes within distributed systems, particularly for managing high volumes of data under substantial loads.
How does Redis sharding work?
Sharding in Redis efficiently disperses data throughout multiple nodes by splitting the keyspace into 16,384 hash slots and allocating them to nodes through consistent hashing.
What are the advantages and limitations of Redis sharding?
Enhancing performance, providing high availability, and offering scalability are benefits of employing sharding in Redis. This approach necessitates client-side support and is constrained by limited support for multi-key operations as well as only accommodating a single database.
What is Redis Cluster and how does it work?
Redis Cluster represents a built-in sharding mechanism within Redis that seamlessly partitions data across multiple nodes while promoting high availability via configurations of master and replica servers.
The structure enhances the scalability and resilience against failures in the Redis environment.
How can I scale my Redis deployment?
For expanding your Redis setup, think about utilizing managed Database-as-a-Service (DBaaS) platforms such as ScaleGrid. This approach streamlines the scaling procedure and allows for dynamic expansion of resources with only a slight interruption in service.



