
Do you want to know why a PostgreSQL query is slow? Then EXPLAIN ANALYZE is a great starting point. But queries can depend on other server activity, can take a while to run, and can change over time, so if you want to see the actual execution plan of your slowest queries, auto_explain is the tool you need. In this post, we’ll look into what it does, how to configure it, and how to use those logs to speed up your queries.
What is Postgres auto_explain?
auto_explain is a PostgreSQL extension that allows you to log the query plans for queries slower than a (configurable) threshold. This is incredibly useful, since it enables you to track unexpectedly slow queries when they occur.
LOG EXECUTION PLANS OF SLOW STATEMENTS AUTOMATICALLY
PostgreSQL auto_explain provides a way of logging execution plans of slow statements automatically without having to manually run EXPLAIN. It is one of the contribution modules, so can be installed and configured easily on regular PostgreSQL, and is so useful that we have it on by default on ScaleGrid.
TRIGGER EXECUTION STATISTICS ARE INCLUDED IN THE LOG OUTPUT
Huge thanks to Takahiro Itagaki, the main author behind the first version of auto_explain (commit, thread), Dean Rasheed, whose initial patch and suggestion it was based on, and the many contributors and reviewers to it since.
Which auto_explain parameters should I use?
There are several configuration parameters, but below we’ll discuss the most important ones. Please review the table below, or the official documentation, for more information on the full array of things you can track.
Use auto_explain.log_min_duration to get the minimum statement execution time in ms query text
The most important parameter for auto_explain is log_min_duration. By default this is set to -1, which means nothing will be logged – so if we want some logs we need to change it! The default unit is ms, so a setting of 100 will log the execution plan for all queries that exceed 100ms.
Note that the default behavior of auto_explain is to do nothing, therefore, you have to at least set auto explain.log min duration if you want any results.
This is what we chose as default in ScaleGrid, but it can be configured under Admin -> Config. If, for some reason, you want to log the execution plan for every query, you can set this to 0 – but beware, this can have severe performance implications.
Get explain analyze output with log_analyze
Since the queries are already being executed on the server, you probably also want to enable auto_explain.log_analyze. This makes the output equivalent to running EXPLAIN ANALYZE. By default, it also means that per-operation timings are tracked for all statements executed.
This comes with some additional overhead that can slow down queries significantly, which can be minimised by turning off auto_explain.log_timing (on by default with log_analyze). Naturally though, per-operation timings are very useful when debugging slow queries! Our internal testing showed acceptable overheads for this, so it is on by default in ScaleGrid, but as ever please test your workload to see if the overhead is acceptable in your case.
There is currently limited publicly available information on this topic, but a recent post by the pgMustard team showed that, at least on a small transactional workload, the overhead can be as low as 2%. As they noted, this could be reduced with the auto_explain.sample_rate parameter, at the cost of only tracking a subset of your queries.
Select the explain output format you prefer
The final parameter we’ll discuss in a bit of detail is auto_explain.log_format. The default query text output is TEXT, which is likely what you’re most familiar with from using EXPLAIN. Other allowed values are JSON, XML and YAML.
Here is a simple example of what auto_explain output in TEXT format can look like:
2021-09-10 15:32:04.606 BST [22770] LOG: duration: 3184.383 ms plan: Query Text: select * from table1 order by column1; Sort (cost=12875.92..13125.92 rows=100000 width=37) (actual time=2703.799..3055.401 rows=100000 loops=1) Sort Key: column1 Sort Method: external merge Disk: 4696kB Buffers: shared hit=837, temp read=587 written=589 -> Seq Scan on table (cost=0.00..1834.01 rows=100000 width=37) (actual time=0.033..27.795 rows=100000 loops=1) Buffers: shared hit=834
auto_explain.log_buffers indicates whether buffer usage statistics should be printed
This parameter is equivalent to the BUFFERS option of EXPLAIN. It has no effect unless auto_explain.log_analyze is enabled. This parameter is off by default and only superusers can change it.
Use sample_rate to explain a fraction of the statements
The default value of auto_explain.sample_rate is 1 and it explains all queries in each session. In case of nested statements, which are statements executed inside a function, either all will be explained or none of them.
You can see here that you get the query duration at the beginning, which you may be used to seeing at the end of query text usually. You’ll also see the query text, including any parameters.
The popular visualisation tools explain.depesz and explain.dalibo both accept query in TEXT format, but they also both support JSON format. If some of your team prefer to use tools like PEV and pgMustard, that only support the JSON format, you might wish to set that as the format. For customers on ScaleGrid we opted for the JSON format, partly as we wanted to parse it more easily for our own slow query plan analysis feature.
See how the Slow Query Analyzer for PostgreSQL Hosting at ScaleGrid can help you quickly visualize and optimize your query performance.
Here is a full list of the auto_explain configuration parameters, and their defaults:
| Parameter | PostgreSQL defaults | ScaleGrid defaults |
|---|---|---|
| auto_explain.log_min_duration | -1 | 100 |
| auto_explain.log_analyze | Off | On |
| auto_explain.log_timing | On (with log_analyze) | On |
| auto_explain.log_buffers | Off | On |
| auto_explain.log_verbose | Off | On |
| auto_explain.log_triggers | Off | Off |
| auto_explain.log_nested_statements | Off | Off |
| auto_explain.log_settings (v12) | Off | Off |
| auto_explain.log_wal (v13) | Off | Off |
| auto_explain.log_format | TEXT | JSON |
| auto_explain.log_level | LOG | LOG |
| auto_explain.sample_rate | 1 | 1 |
Installing auto_explain
On ScaleGrid, auto_explain is on by default, with a threshold of 100ms. You can configure this under Admin -> Config.
On vanilla PostgreSQL, you can install auto_explain simply by adding it to one of session_preload_libraries or shared_preload_libraries. The former has the advantages of a) not requiring a restart (but it’ll only be loaded in new sessions) and b) making it possible to enable it only for some users (by setting this parameter with ALTER ROLE SET).
As such, a basic config set-up for auto_explain could look like this:
session_preload_libraries = auto_explain auto_explain.log_min_duration = 100 auto_explain.log_analyze = true auto_explain.log_buffers = true auto_explain.log_format = JSON
If you’re using a different hosting provider, it’s worth checking whether they support auto_explain. For example, RDS Postgres does, but unlike ScaleGrid, it is off by default, so you’ll need to edit the configuration to get it running.
Loading auto_explain into a single session
If you don’t want auto_explain running in sessions automatically, as a superuser you also have the option of loading it into a single session:
LOAD 'auto_explain';
This can be incredibly useful for one-off debugging sessions but naturally is unnecessary if you are able to have it running already.
auto_explain limitations and gotchas
We have mentioned some of these in passing already, but it seems a sensible time to remind ourselves of some of the downsides and limitations of auto_explain.
Firstly, especially when tracking per-operation timings, there can be measurable overhead to using auto_explain. It can be low, even with timings being measured, but as ever it’s worth doing your own testing.
Secondly, auto_explain timings are exclusive of query planning time. Planning time is often tiny on slow queries, but in exceptional cases, it can be responsible for the majority of the issue.
As such, bear in mind that these cases may not show in your logs, or if they do, a discrepancy with what you’re seeing in total latency might be to do with the planning time. A manual EXPLAIN ANALYZE will quickly help you spot this.
How to use the EXPLAIN output to speed up queries
Once you have the explain output for your slowest queries, you can now start looking into speeding them up!
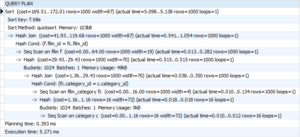
You’ll need to get the query execution plan out of the logs, which you can use pgBadger for if you’re not using a managed service that does this for you.
Reviewing EXPLAIN plans is a huge topic in its own right. The PostgreSQL documentation includes a good but brief introduction to using EXPLAIN, and Thoughbot’s article on reading EXPLAIN ANALYZE is a good next step. If you’d prefer an hour-long talk, EXPLAIN Explained by Josh Berkus is excellent. For more information, Depesz has a series of posts called Explaining the unexplainable and the pgMustard team have a fairly comprehensive EXPLAIN Glossary.
USE SCALEGRID TO OPTIMIZE YOUR SLOW QUERIES
If you need help from PostgreSQL experts to manage your databases and speed up your slow queries, give ScaleGrid a try. We provide different support plans that gives you access to our database experts who can guide you through these slow queries and help you get them all optimized. Our free 30-day trial gives you plenty of time to try out our many features for PostgreSQL and our other supported databases.
READ ALSO:
- PostgreSQL EXPLAIN
- How to Install PostgreSQL 12 on Ubuntu 20.04 DigitalOcean
- Best PostgreSQL GUI Comparison
We hope this gives you everything you need to get started with auto_explain and start speeding up any slow queries you have. If there’s anything else you’d like to know, do get in touch.



