In our previous posts in this series, we spoke at length about using PgBouncer and Pgpool-II, the connection pool architecture and pros and cons of leveraging one for your PostgreSQL deployment. In our final post, we will put them head-to-head in a detailed feature comparison and compare the results of PgBouncer vs. Pgpool-II performance for your PostgreSQL hosting!
How do the features stack up?
Let’s start by comparing PgBouncer vs. Pgpool-II features:
| PgBouncer | Pgpool-II | |
|---|---|---|
| Resource consumption | It uses only one process which makes it very lightweight. PgBouncer guarantees a small memory footprint, even when dealing with large datasets. Winner! | If we require N parallel connections, this forks N child processes. By default, there are 32 child processes that are forked. |
| When are connections reused? | PgBouncer defines one pool per user+database combination. This is shared between all clients, so a pooled connection is available to all clients. Winner! | Pgpool-II defines one process per child process. We cannot control which child process a client connects to. A client benefits from a pooled connection only if it connects to a child which has previously served a connection for this database+user combination. |
| Pooling modes | PgBouncer supports three different modes: session (connection returned to pool when client disconnects), transaction (returned to pool when client commits or rollbacks) or statement (connection returned to pool after the execution of each statement). Winner! | Pgpool-II supports only session pooling mode – efficacy of pooling is dependent on good behavior from clients. |
| High availability | Not supported. | PostgreSQL high availability is supported through Pgpool-II in-built watcher processes. Winner! |
| Load balancing | Not supported – PgBouncer recommends use of HAProxy for high availability and load balancing. | Supports automatic load balancing – is even intelligent enough to redirect read requests to standbys, and writes to masters. Winner! |
| Multi-cluster support | One PgBouncer instance can front several PostgreSQL clusters (one-node or replica-sets). This can reduce the cost for middleware when using multiple PostgreSQL clusters. Winner! (Note – this advantage is only for specific scenarios) | Pgpool-II does not have multi-cluster support. |
| Connection control | PgBouncer allows limiting connections per-pool, per-database, per-user or per-client. Winner! | Pgpool-II allows limiting the overall number of connections only. |
| Connection queue | PgBouncer supports queuing at the application level (i.e. PgBouncer maintains the queue). Winner! | Pgpool-II supports queuing at kernel level – this can cause pg_bench on CentOS 6 to freeze. |
| Authentication | Pass-through authentication is supported through PgBouncer. Winner! | Pgpool-II does not support pass-through authentication – users and their md5 encrypted passwords must be listed in a file and manually updated every time a user updates their password.Pgpool-II does support passwordless authentication through PAM or SSL-certificates. However, these must be set up outside the PostgreSQL system, while PgBouncer can offload this to the PostgreSQL server. |
| Administration | PgBouncer provides a virtual database that reports various useful statistics. | Pgpool-II provides a detailed administration interface, including a GUI. Winner! |
| Host-based authentication | Supported. Tied! | Supported. Tied! |
| SSL support | Full support. Tied! | Full support. Tied! |
| Logical replication | Not supported through PgBouncer. Tied! | Supported through Pgpool-II, but this is done by sending the write queries to all nodes, and is not generally recommended. Tied! |
| License | ISC – very permissive, basically allows all usage. Tied! | Custom license – equally permissive. Tied! |
The bottom line – Pgpool-II is a great tool if you need load-balancing and high availability. Connection pooling is almost a bonus you get alongside. PgBouncer does only one thing, but does it really well. If the objective is to limit the number of connections and reduce resource consumption, PgBouncer wins hands down.
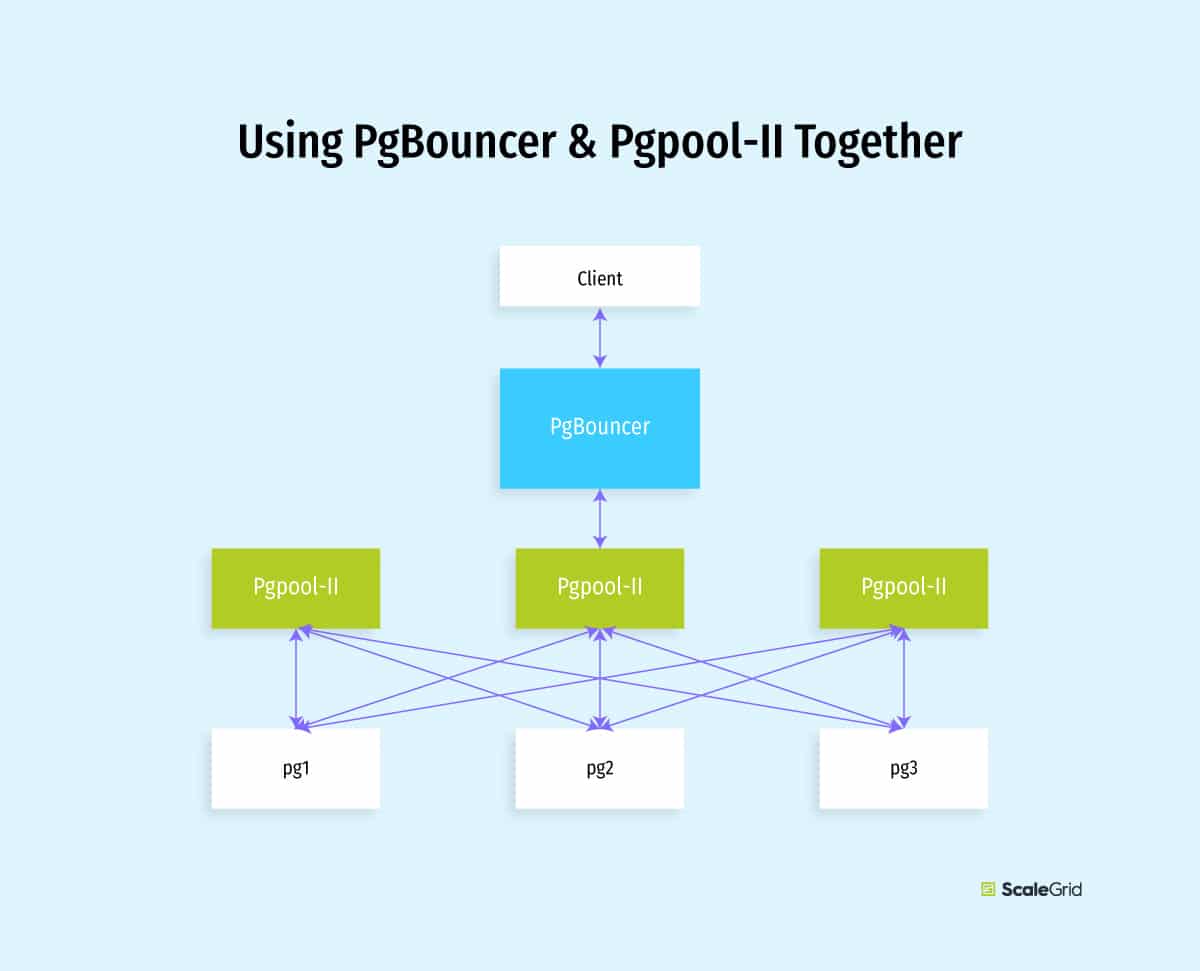
It is also perfectly fine to use both PgBouncer and Pgpool-II in a chain – you can have a PgBouncer to provide connection pooling, which talks to a Pgpool-II instance that provides high availability and load balancing. This gives you the best of both worlds!
Performance Testing
While PgBouncer may seem to be the better option in theory, theory can often be misleading. So, we pitted the two connection poolers head-to-head, using the standard pgbench tool, to see which one provides better transactions per second throughput through a benchmark test. For good measure, we ran the same tests without a connection pooler too.
Testing Conditions
All of the PostgreSQL benchmark tests were run under the following conditions:
- Initialized pgbench using a scale factor of 100.
- Disabled auto-vacuuming on the PostgreSQL instance to prevent interference.
- No other workload was working at the time.
- Used the default pgbench script to run the tests.
- Used default settings for both PgBouncer and Pgpool-II, except max_children*. All PostgreSQL limits were also set to their defaults.
- All tests ran as a single thread, on a single-CPU, 2-core machine, for a duration of 5 minutes.
- Forced pgbench to create a new connection for each transaction using the -C option. This emulates modern web application workloads and is the whole reason to use a pooler!
We ran each iteration for 5 minutes to ensure any noise averaged out. Here is how the middleware was installed:
- For PgBouncer, we installed it on the same box as the PostgreSQL server(s). This is the configuration we use in our managed PostgreSQL clusters. Since PgBouncer is a very light-weight process, installing it on the box has no impact on overall performance.
- For Pgpool-II, we tested both when the Pgpool-II instance was installed on the same machine as PostgreSQL (on box column), and when it was installed on a different machine (off box column). As expected, the performance is much better when Pgpool-II is off the box as it doesn’t have to compete with the PostgreSQL server for resources.
Throughput Benchmark
Here are the transactions per second (TPS) results for each scenario across a range of number of clients:
| Number of clients | Without pooling | PgBouncer | Pgpool-II (on box) | Pgpool-II (off box) |
|---|---|---|---|---|
| 10 | 16.96 | 26.86 | 15.52 | 18.22 |
| 20 | 16.97 | 27.19 | 15.67 | 18.28 |
| 40 | 16.73 | 26.77 | 15.33 | 18.3 |
| 80 | 16.75 | 26.64 | 15.53 | 18.13 |
| 100 | 16.51 | 26.73 | 15.66 | 18.45 |
| 200 | Connections aborted. | 26.93 | Connections aborted when max-children > 200, pgbench hangs at max-children value if <= 100. | Connections aborted when max-children > 200, pgbench hangs at max-children value if <= 100. |
Pgpool-II hangs when pg_bench is run with more clients than max_children. So, we increased the max_children to match the number of clients for each test run.
If we calculate the percentage increase in TPS when using a connection pooler, here’s what we get:
| Number of clients | PgBouncer | Pgpool-II (on box) | Pgpool-II (off box) |
|---|---|---|---|
| 10 | 58.37% | -8.49% | 7.43% |
| 20 | 60.22% | -7.66% | 7.72% |
| 40 | 60.01% | -8.37% | 9.38% |
| 80 | 59.04% | -7.28% | 8.24% |
| 100 | 61.90% | -5.15% | 11.75% |
* Improvement algorithm = (with pooler – without)/without
Final Words
As you can see from the performance test results, a well-configured connection and well-suited connection pooler can drastically increase the transaction throughput, even with a fairly small number of clients. Connection poolers are especially useful for their queuing support – when the number of clients exceeds the max-clients supported by PostgreSQL server, PgBouncer is still able to maintain the transaction rate, whereas direct connections to PostgreSQL are aborted.
However, a badly configured connection pooler can actually reduce the performance as we saw with the Pgpool-II setup here. Part of the problem is, using Pgpool-II doubles the number of processes running on the same server – we must run Pgpool-II on a separate server to get a good performance. But even then, PgBouncer manages to provide better performance for these relatively small numbers of clients.
Also, note the test here was actually perfectly crafted for Pgpool-II – since when N > 32, the number of clients and number of children processes were the same, and hence, each reconnection was guaranteed to find a cached process. Even then, PgBouncer was the faster alternative.
So, our testing indicates PgBouncer is the far better choice for connection pooling. But, it’s important to remember that while a connection pooler is absolutely mandatory for most realistic workloads, whether you gain more by using a client-side pool or middleware such as PgBouncer depends on your application. Patterns of data access would play a role, as would the latencies involved based on your architecture. We recommend testing your workload against both, and then decide on the best course of action – there is no better alternative to experimentation!



