
Greenplum Database is a massively parallel processing (MPP) SQL database built on PostgreSQL. It can scale to a multi-petabyte-level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data.
In this blog post, we explain Greenplum, break down its architecture, advantages, major use cases, and how to get started.
What Exactly is the Greenplum Database?
Greenplum Database is an open-source, hardware-agnostic MPP database for analytics based on PostgreSQL and developed by Pivotal, which was later acquired by VMware. Its MPP architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
The Greenplum Architecture
To understand the Greenplum architecture better, let’s first look at what an MPP database is.
What is an MPP Database?
When handling large amounts of complex data, or big data, your main machine might start getting crushed by all the data it has to process to produce your analytics results. Many organizations are considering adopting an MPP database to fill this need for faster processing and enable quicker results.
The Massively Parallel Processing – MPP System
The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel. It uses several processing units that work independently using their dedicated memory and resources, so the workload is shared across multiple devices instead of just one.
Typically an MPP system has one leader node and one or many compute nodes. The leader node, called “master” in Greenplum, tells all the other nodes, called “segments”, what to do and amalgamates their responses to create the final answer.
MPP databases scale horizontally by adding more computing resources (nodes) rather than worrying about upgrading to more expensive individual servers (scaling vertically).
Greenplum Architectural Design
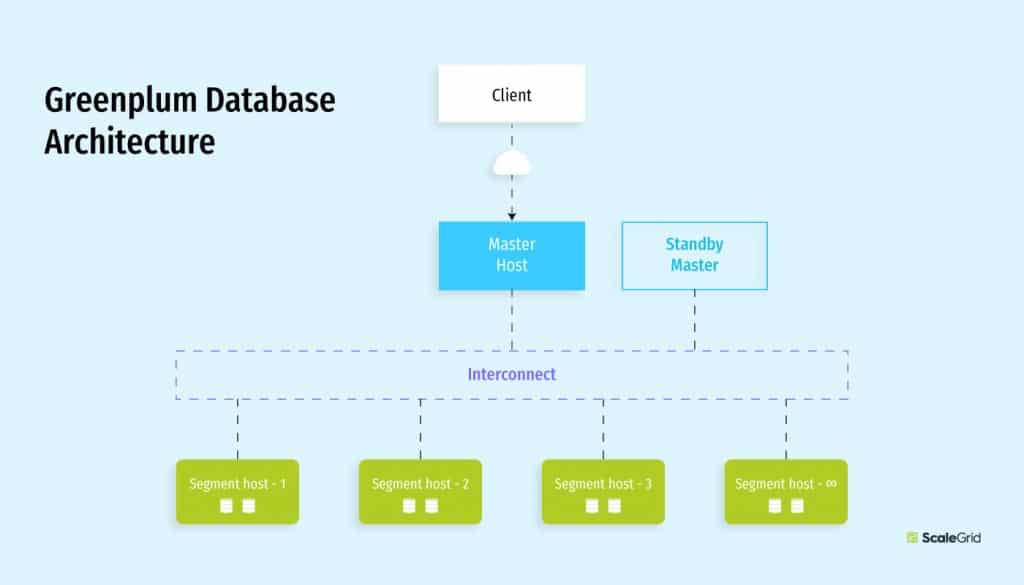
Based on the PostgreSQL architecture, Greenplum essentially leverages several PostgreSQL database instances at a time in one single Greenplum cluster. PostgreSQL users can quickly familiarize themselves with this database type, as many of the features, configurations, and functionality are the same in Greenplum, and include features designed to optimize how PostgreSQL works for business intelligence (BI) tasks and workloads.
Leverage existing SQL knowledge
Greenplum also introduced many features unavailable within PostgreSQL, such as parallel data loading, resource management, storage enhancements, and advanced query optimization, making it an attractive offering when compared to the latter.
Similarly to PostgreSQL, Greenplum leverages one master server, or host, which is the entry point to the database, accepting connections and SQL queries. However, where PostgreSQL leverages standby nodes to geographically distribute their deployment, Greenplum uses segment hosts that store and process the data.
Greenplum segments are independent and each stores a portion of the data, though handle a majority of the query processing. You can leverage as few as two segment hosts and scale to an unlimited capacity. If you have mirroring enabled, you must increase your segment hosts in increments of at least two.
By offering you a single, scale-out environment for integrating analytical and operational workloads, like streaming ingestion, and batch mode analytics, Greenplum aids in the elimination of data silos.
So, how is this all coordinated? Greenplum interconnect is the networking layer of the MPP architecture, and manages communication between the Greenplum segments and master host network infrastructure.
Greenplum Advantages
Here are some of the key Greenplum advantages that can help you improve your database performance:
High Performance
Greenplum has a uniquely designed data pipeline that can efficiently stream data from the disk to the CPU, without relying on the data fitting into RAM, as explained in their Greenplum Next Generation Big Data Platform: Top 5 reasons article.
This provides Greenplum deployments with a huge performance boost over in-memory systems that need enough memory to store their data or non-RDBMS-based systems that are in-memory processing engines that allocate RAM for each concurrent query. Greenplum’s high performance eliminates the challenge most RDBMS have scaling to petabyte levels of data, as they can scale linearly to efficiently process data.
Query Optimization
Greenplum features a cost-based query optimizer for large-scale, big-data workloads. Tapping into performance as we covered above, Greenplum scales interactive and batch mode analytics to the petabyte scale without degrading the query performance. The cost-based query optimizer allows Greenplum to distribute the load between their different segments and use all of the system’s resources parallelly to process a query.
Additionally, with OLTP (Online Transactional Processing) workload improvements in Greenplum 6, single query performance has improved over 3.5c over Greenplum 5. With this update, Greenplum eliminated a lot of the lock competition so master CPU usage can exceed 90% which improves the performance of the query by improving the hardware performance of the master node.

Open Source
Greenplum Database is an open-source data warehouse project based on PostgreSQL’s open-source core, allowing users to take advantage of the decades of expert development behind PostgreSQL, along with the targeted customization of Greenplum for big data applications. Greenplum can run on any Linux server, whether it is hosted in the cloud or on-premise, and can run in any environment.
While Greenplum is maintained by a core team of developers with commit rights to the main repository, they are eagerly welcoming new contributors who are experienced with the database to help shape Greenplum’s future. Learn more about getting involved through the Greenplum GitHub page.
Polymorphic Data Storage
Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time. This will allow you to design your tables based on the way your specific data is accessed and in turn, have a row or column-oriented storage hierarchy.
When you create a table in Greenplum, you can control the orientation with the ability to choose either column-oriented or row-oriented data. Column-oriented is typically better for full scans, while row-oriented is better for small scans or lookups.
Greenplum even allows you to create domain-specific data types and functions. Through the use of semi-structured data types, which include XML, HStore, and JSON, you can store and analyze both structured and unstructured data within a database.
Major Use Cases
Greenplum provides a powerful combination of massively parallel processing databases and advanced data analytics which allows it to create a framework for data scientists and architects to make business decisions based on data gathered by artificial intelligence and machine learning. Let’s walk through the top use cases for Greenplum:
Advanced Data Analytics
The advanced analytics provided by Greenplum is being used across many verticals, including finance, manufacturing, automotive, government, energy, education, retail, and so on, to address a wide variety of problems.
Some of the Greenplum Database analytics capabilities highlighted by Pivotal include the ability to analyze a multitude of data types, leverage existing SQL knowledge, and train more models in less time by using the MPP architecture.

Additionally, Greenplum provides in-database analytics which allows you to run analytics directly in the database vs. exporting and running your data in an external analytics engine.
As a database tailored towards enterprise workloads, this provides the ability needed to explore large data sets along with the high performance achieved by paralleling the analytics across your available segment hosts. You can also leverage a wide range of power analytics tools with Greenplum, including MADlib, R statistical language, SAS, and Predictive Modeling Markup Language (PMML).
For example, a billion-dollar scale Internet Marketing company is using Greenplum advanced analytics to perform audience profiling to understand who their audience is, what they buy, which networks and devices they use, and where they are geographically located so they can better understand and serve their market.
Machine Learning
Greenplum is an excellent database for machine learning – the study of computer algorithms that improve automatically through experience. Apache MADlib is an open-source, SQL-based machine learning library that runs in-database on Greenplum, as well as PostgreSQL.
This combination helps you improve the parallelism, scalability, and predictive accuracy of your Greenplum machine-learning deployment. Data transformation and feature engineering capabilities are also available through MADlib for machine learning, including descriptive and inferential statistics, pivoting, sessionization, and encoding categorical variables.
For example, a Government fraud revenue retention company is leveraging Greenplum machine learning capabilities along with GemFire to perform large-scale fraud detection to prevent identity theft, detecting and retaining $5B annually and processing 8 million cases a day.
AI

Artificial intelligence (AI), while similar to machine learning, refers to the broader idea that machines can execute tasks smartly. Greenplum is a great database choice for applications looking to mimic human abilities through smart machines.
Greenplum’s ability to ingest large volumes of data at high speeds, makes this database a powerful tool for smart applications that need to interact intelligently based on an unlimited number of unique scenarios.
For example, a Telecom company is using Greenplum database AI capabilities for their IoT operational reporting system smart sensors to analyze and execute events used for maintenance, security, and operational efficiencies.
So who’s using Greenplum today? Greenplum customers include American Express, Walmart, Asurian, Bank of America, and many more across the banking, professional services, media, insurance, healthcare, automotive and retail markets.
How to Get Started
As mentioned throughout this post, Greenplum is an open-source database, so the community version is free to download and use. Greenplum’s small but active community welcomes new contributors, accepts feedback, and collaborates with Greenplum evangelists to promote the big data database.
Many organizations leveraging Greenplum seek additional support and tools to help their DBAs manage their deployments. Here are the two different database management and support options available for Greenplum:
ScaleGrid for Greenplum® Database – Open Source Version
ScaleGrid for Greenplum® Database is a fully managed solution for the open-source version of Greenplum, launching in May 2020. The multi-cloud platform allows you to deploy and manage on AWS, Azure Google Cloud (coming soon) cloud platforms, or VMware on-premise environments.
ScaleGrid provides Greenplum users with the advanced management tools they need to deploy in a single click, automate backups, and scale dynamically with the ability to maintain full super-user admin privileges over their open-source deployments.
Pivotal Greenplum – Commercial Version
Pivotal Greenplum, now VMware Tanzu is the creator behind the open-source database that offers a commercial version to help you deploy and manage Greenplum in the cloud and on-premise. Pivotal Greenplum offers many advantages, such as maximizing uptime, protecting data integrity, and easily handling streaming and cloud data.
Both ScaleGrid and Pivotal Greenplum offer advanced support packages to help your DBAs optimize their Greenplum deployments.



