
MongoDB 3.0 with the WiredTiger storage engine enables you to transparently compress the data stored in your database. This is a fairly exciting and useful feature that can be used to reduce the disk space usage of your fast-growing data. By default wired tiger uses the ‘Snappy’ block compression engine for all the collections. You can turn off compression by default using the following options in the MongoDB server config file.
storage:
engine: wiredTiger
wiredTiger:
collectionConfig:
blockCompressor: none
The compression algorithm can be specified at the collection level during cluster creation. Here is an example of creating a collection with ‘zlib’ compression:
db.createCollection("test", {storageEngine: {wiredTiger: {configString: 'block_compressor=zlib'}}});
MongoDB WiredTiger storage engine provides two options for compression – snappy and zlib. There is essentially a tradeoff between the extent of compression and the amount of CPU load to decompress. ‘Zlib’ achieves a lot more compression and is correspondingly less performant. ‘Snappy’ aims for ‘aims for very high speeds and reasonable compression’.
We ran some simple unscientific tests to measure the compression performance. We used one of data sets storing strings which we felt would compress well. Here is the basic structure of each document:
{
'_id': <ObjectID>,
'name': <Five character string>,
'value': <Random 1MB string>
}
We inserted about 5000 of these documents (about 5GB of data)., and the results were fairly impressive. Zlib achieves a considerable amount of compression. Snappy also achieves a fair amount of compression with little or no load on the system:
| Zlib | Snappy | uncompressed | |
| Data size (MB) | 5000.5 | 5000.5 | 5000.5 |
| Storage size (MB) | 19.62 | 254.37 | 5019 |
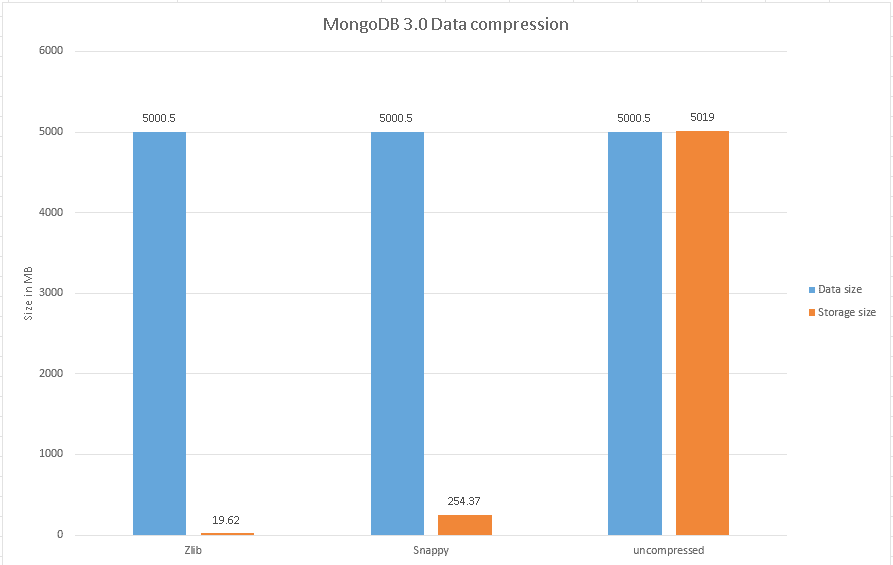
As always you need to run some tests to understand the performance gains for your data set. Here are some more detailed benchmark studies on compression performance and tradeoffs:
http://www.mongodb.com/blog/post/new-compression-options-mongodb-30
http://www.acmebenchmarking.com/2015/02/mongodb-v30-compression-benchmarks.html
Read Also:
Cassandra Vs. MongoDB
Reducing Your Database Hosting Costs: DigitalOcean vs. AWS vs. Azure
How to enable logging for Mongoose and the MongoDB Node.JS driver



