
One of the things that often confuses users who are familiar with other databases when they try the Redis server is the lack of visibility into the database.
There is no set of tables or collections to see, just a plain, flat key space that could (potentially) have millions of keys. The ability to iterate cheaply over this key space becomes very important to familiarize oneself with the database contents.
6 Crucial Redis Monitoring Metrics You Need To Watch
Iterating over the Redis CLI (Command Line Interface) keyspace has other important use cases. A few that come to mind are:
- Garbage collection or cleaning up keys with a certain keys matching pattern.
- Data movement and schema changes or moving a certain set of keys to another data store
- Debugging, data sampling, data fixes, or finding and fixing all keys that were messed up by a recent change
In this post, we will dig deep into various key space iteration options available in Redis.
O(N) Iterators: KEYS

In Redis, the ability to get all keys stored in the Redis database can be invaluable for various use cases.
Unlike traditional relational databases that use tables to organize data, Redis employs a plain, flat key space to store its data. This key space can potentially contain millions of keys, making it essential to have a mechanism to retrieve all the keys.
Redis Get All Keys Command – Retrieving All the Keys in Redis
Are you wondering which command is used to obtain all the keys in a database like Redis? One straightforward way to retrieve all keys is by using the KEYS command. This command is used to retrieve all the keys in the database that match a specified pattern or, if not specified, all keys in the entire key space. It works by scanning the dictionary where Redis stores its keys and sends everything that matches the pattern as a single array reply.
Considerations when using the Redis KEYS command
However, it’s important to exercise caution when using the command, especially in environments with a large number of keys. The performance of this operation is dependent on the size of the key space and can be linear (O(N)), where N is the number of keys, provided that the key names in the database and the given pattern have limited length.
Since the Redis database is single-threaded, running the KEYS command can block other operations, ruin performance-critical scenarios, and should generally be avoided in production environments. Therefore, it’s recommended to use it in a Redis instance primarily for debugging or in special cases where performance is not a concern.
The other important thing to remember about this algorithm is that it sends out all the matching keys together as a single response. This might be extremely convenient when the key space is small but will create multiple issues on a large key space. KEYS, however, is a favorite command among developers in their own dev environments.
Redis Get All Keys Example
Here’s a basic example where we set four key-value pairs in a Redis server and then query the database to retrieve specific sets of keys:
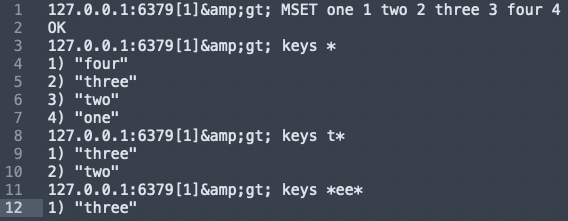
In the above code snippet, we typed into Redis CLI:
![]()
The MSET command sets multiple keys to multiple values in the Redis database.
one is set to 1, two is set to 2, etc.
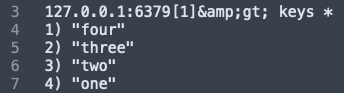
keys *:
We used the keys prefix: * to get all keys stored in the current Redis server.

keys t*:
Get all keys that begin with the letter ‘t’.
![]()
keys ee:
Get all keys that contain the substring ‘ee’.
Cursor-Based Iterators: SCAN
There are various commands in Redis CLI for key space iteration, and one of the most versatile options is SCAN. This command, along with its sister commands like SSCAN (for sets), HSCAN (for hashes and hash key values), and ZSCAN (for sorted sets), introduces a cursor-based approach to iteration in Redis data structures. These features have been available in Redis since version 2.8.0.
When using SCAN, keys are returned in incremental iterations, with a constant time guarantee for each cycle. A cursor (an integer in this case) is returned when the iterations are initialized, and an updated cursor is returned with every loop.
An iteration cycle begins when the cursor is set to 0 in the SCAN request and terminates when the cursor returned by the server is 0. However, due to nuances in the Redis architecture and the algorithm’s implementation, there are some peculiarities of this approach:
- A full iteration cycle always retrieves all the elements that were present in the collection from the start to the end of that cycle.
- A full iteration cycle never returns any element that was NOT present in the collection from the start to the end of that cycle.
- A given element may be returned multiple times. It is up to the application to handle the case of duplicated elements.
- Elements that were not constantly present in the collection during a full iteration may be returned or not; it is undefined.
- The number of elements returned during each count varies and can be 0 too. However, the iteration is not complete until the server returns the cursor value of 0.
- The COUNT option can be used to limit the number of elements returned in each iteration. The default value is 10. However, it is considered only a suggestion and not enforced in all cases. The COUNT value can be changed during each iteration call.
- The MATCH option allows specifying patterns, similar to what the KEYS command allows.
The cursor implementation is completely stateless on the server side. This allows (potentially) infinite iterations to start in parallel. Also, there are no requirements to ensure that an iteration continues up to the end and can be stopped anytime.
Despite its peculiarities, the SCAN command is a very useful command and the right command to pick for key space iterations in Redis, especially when dealing with large databases and complex data store structures.
SCAN is a very useful command and the right command to pick for key space iterations in Redis.
SCAN in Action
127.0.0.1:6379[1]> flushdb
OK
127.0.0.1:6379[1]> keys *
(empty list or set)
127.0.0.1:6379[1]> debug populate 33
OK
127.0.0.1:6379[1]> scan 0 COUNT 5
1) "4"
2) 1) "key:1"
2) "key:9"
3) "key:13"
4) "key:29"
5) "key:23"
127.0.0.1:6379[1]> scan 4
1) "42"
2) 1) "key:24"
2) "key:28"
3) "key:18"
4) "key:16"
5) "key:12"
6) "key:2"
7) "key
Under the Hood
The algorithm that SCAN (and its sister commands) use to scan through is an intriguing one and leads to some of the characteristics of the command that we described above.
Antirez described it at a high level in his blog post and it is explained (slightly better) in the comments above the implementation (function dictScan). Describing it in detail will make this post too long so I will give enough description to make its implications evident.
- Most Redis data structures are internally represented as dictionaries. They are implemented as power-of-two-sized hash tables with chaining for collisions. The challenge in writing a cursor-based iterative algorithm here is to be able to deal with the growing and shrinking of the hash without sacrificing the Redis principles of simplicity (of the API) and speed.
- SCAN basically scans a bunch of hash buckets every iteration and returns the elements matching the pattern in those. Since it looks at only a fixed list of buckets, sometimes iterations might return no values at all.
- The cursor that is returned is basically an offset into the hash table being iterated. It deals with the growing and shrinking of hash tables (i.e. rehashing) by clever manipulation of higher-level bits of the offset while increasing the offset along with the properties of the table. Implications from this approach are that new elements added during the iteration may or may not be returned. However, the cursor itself, wouldn’t need to restart on a change in size of the hash table.
- A given bucket must be visited just once and all its keys must be returned in a single go. This is again to ensure that hash resizing (i.e. rehashing) doesn’t complicate iteration progress. However, this leads to the COUNT argument not being strictly enforceable.
- Since the above approach is completely stateless on the server side, it basically implies that iterations can be stopped or a huge number of iterations can be started in parallel without any increased memory usage.
[clickToTweet tweet=”To iterate over #Redis key space, use KEYS when performance isn’t a concern, otherwise use SCAN” quote=”To iterate over #Redis key space, use KEYS when performance isn’t a concern, otherwise use SCAN”]
Beyond key iteration, Redis plays a central role in powering AI features such as vector search, real-time inference, and semantic caching. If you’re working on projects involving large-scale data retrieval, natural language processing, or recommendation engines, explore how Redis supports AI-driven applications that go far beyond traditional key-value storage.
Summary
At a high level, two Redis commands are available to iterate over keys:
- Use KEYS when performance is not a concern or when the key space is reasonably sized to get all the keys.
- At all other times, use SCAN.
Here are some of our other posts in the Redis data structures series:
Did you know we support hosting for Redis™*? Get fully managed hosting for Redis™ in the safety of your own cloud account, and leverage AWS/Azure credits for your Redis™ deployments with our Bring Your Own Cloud option.



