
It is estimated that the average person generates approximately 1.7 megabytes of data every minute and about 50 gigabytes every month. With so much data being generated every day, companies are all looking for ways to improve the dependability of their infrastructure, increase data availability, and reduce downtime.
One technique that organizations have been deploying is database replication. Database replication, sometimes referred to as data replication or data store replication, is the practice of duplicating the data from a primary database living on one server to one or multiple databases hosted on other servers.

As data stores can refer to multiple types of persistent digital storage, know that we are referring to databases specifically. Usually, these duplicated databases are distributed across multiple virtual private servers (VPS) and across multiple regions, allowing for data centers to provide the best possible connection to your data. Database replication can happen in real-time or as a scheduled batch process (a cron job in Unix-like environments). Whichever method you choose depends solely on the requirements of your end users or customers and their access to the same data stored in your principal database.
With all the database management options available, it can be confusing trying to set up a distributed database replication system on your own. As the shift toward cloud computing has gained in popularity, so too has the need for distributed database replication systems. Not to be intimidated, though, as we will give you the knowledge to make informed choices going forward.
Follow along as this guide will help you to understand what database replication is, its benefits, potential risks, and how to implement it.
What is database replication?
Database replication is the infrastructure that enables the distribution of data across multiple databases, on multiple replica servers. Database replication can be implemented so that data from a primary database is copied in real-time, one-time, or batch processes. The end result of database replication is that any changes to data in any one database are reflected across all other databases managed by an organization. This can provide redundancy, data integrity, availability, security, and ease of access for end users.
Distributed database management systems or services (DDBMS) are the foundation of database replication. Database management systems ensure that any changes to any one database are reflected across the entire ecosystem of databases. Typically, this requires the use of one or more applications that connect a single principal database to one or more remote databases.
Increasingly, these databases are hosted on a VPS in the cloud. Some common relational databases (RDBMS) that can benefit from hosted database replication include MySQL, PostgreSQL and Greenplum®. In recent years, non-relational databases (NoSQL), commonly referred to as document databases or document stores, have gained popularity for their simple key-value storage and improved speed. They, too, can benefit from the security of database replication. Some popular document store technologies include Redis™ and MongoDB® database.
Why should I replicate my databases?
The typical reasons an organization will implement database replication processes include improving performance, data integrity, and reducing downtime. Database replication has the added benefit of reducing downtime; it saves time, energy, and money. With properly implemented database replication protocols, teams will spend less time redeploying or restoring databases from backups; time that can be better spent on architecture or coding.
Employing data redundancy measures ensures data availability in that, if one server goes down, a distributed system with replicated databases can still function. This provides uninterrupted access to your data by current and potential customers. Providing continuous data availability to your customers helps ensure there is no loss of profit. Don’t lose the trust of your customers in your organization by not preventing avoidable downtime.
How to implement database replication
Whichever method you choose to implement a database replication strategy in your system, it can come with different advantages. Most database replication methods aim to solve a very similar set of challenges; data integrity, availability, and speed. When choosing a data replication method, key considerations include complexity, technology, and purpose. You’ll likely need to choose between two main types of data transfer; asynchronous and synchronous.
Asynchronous data replication
The asynchronous approach to database replication prescribes that data from a principal data store will be sent to a replica server, oftentimes returning a promise. A promise represents the eventual completion of a transfer, allowing distributed database management systems to monitor the success, progress, or failure of said transfer. It allows the system to attach handlers to eventual success or failure responses.
This method is non-blocking, allowing the system to continue operations while the transfer is happening. This is by far the most flexible approach, allowing data transfers and replication to happen in the background. The risk to data integrity is jeopardized, as confirmation will come prior to the completion of the replication process.
Synchronous data replication
A synchronous approach tends to be a bit slower but safer than asynchronous database replication. This type of system will take data from the principal database, copy it to a model server, and then transfer it to distributed replica servers. This method is functionally block in that the system will continue operations only after the success or failure of the replication process. The benefit of this approach is that it allows for distributed database management systems to only proceed upon the successful completion of a data transfer.
There are a few types of database replication methods that depend on server architecture. Depending on your data requirements, you’ll likely choose one of the following architectures:
Single-leader architecture
Single-leader architecture is structured so that a single principal server receives write requests from any number of clients. Replica servers will pull data and populate themselves from the principal server. This structure ensures consistency in data synchronization.
Multi-leader architecture
Multi-leader architecture prescribes that multiple servers can receive write requests while also serving as models for replica servers. The benefit of this architecture is that when replica data stores are distributed, leaders or principal servers, for the sake of latency, need to be in close proximity.
No-leader architecture
No-leader architecture is when every server can receive and write requests and be a model for replica servers. This structure offers the most flexibility but comes with the highest risk to data integrity.
Database replication techniques
Depending on your organization’s governing data security policies and the sensitivity of the data being replicated; techniques for database replication may vary within an organization. Here are a few common techniques to get familiar with:
Full-table replication
This is probably the slowest data replication technique, but it is the most trustworthy in terms of data integrity. For every data transfer transaction, the entire data set is copied to another database, either on the same machine or a VPS. When facing data loss and faulty database configurations, full-table replication can help restore databases that don’t possess replication keys.
Key-based incremental replication
This method only replicates the data that has changed since the last update. The key-based incremental replication technique incrementally updates your databases, saving resources and reducing the burden placed on servers doing massive rewrites to a database.
Log-based incremental replication
The log-based replication technique is one in which modifications are logged in a log file. These change logs are then used to make updates to the replica data store. Only MySQL, PostgreSQL, and MongoDB® database can benefit from this data replication technique.
What are the advantages of database replication?
Simply put, database replication prevents downtime, enables data availability, ensures data integrity, and saves time and money. While one server may go down, a distributed database replication system can continue to operate without skipping a beat. Making use of database replication and implementing it correctly has its advantages.
Distributing your data across multiple data stores around the world helps combat latency issues that typically accompany client requests from great distances. By distributing data, the likelihood of one server being overburdened with requests is minimized. This leads to increased performance across the entire system.
While database replication can be great for ensuring the availability of your organization’s data; it can also ensure data consistency. Changes made to a principal database are reflected in distributed databases, making your data trustworthy.
Disaster recovery is a key component of distributed database replication systems. When organizations suffer from data loss, deletion, and data corruption, having replica data serves as a backup of data. A lot of cloud database hosting and management services will oftentimes take snapshot images of your instances, allowing for quick recovery from data breaches and system corruption. Regularly replicating databases to removable media is often the best defense against threat actors and malware.
Are there any disadvantages to database replication?
While there are a lot of advantages to database replication that are worth investing in, there are some risks to be aware of too. Most issues that arise in a distributed database replication system come from poor execution or bad data governance policies. If possible, switch to a database-as-a-service provider to greatly reduce your organization’s exposure to risks.
The most important risk to any organization is the potential for data loss. This often happens as a result of improperly configured principal, model, or replica databases. Conflicting or incorrect primary keys, used to ensure the quality of data, can also be attributed to lost or incomplete data. Data loss can also occur at the point of replication by sourcing incorrect or out-of-date data.
A database replication system that does not ensure the synchronization of data across all database replicas can lead to data inconsistencies.
There are inherent costs associated with operating and maintaining multiple servers. Either your organization or a third-party service will need to absorb that cost. Consider that your organization may be subject to vendor lock-in and can suffer from service continuity issues. Using a third-party service may result in unpreventable downtime, so it’s important to choose a company with a proven track record and trusted assurances.
How can I set up database replication?
Depending on which database technologies your organization is using for its data store, there are likely a variety of tools and services that can help you implement database replication quickly and securely. While setting up database replication systems can be complex and challenging, there are third-party services that can help reduce the barrier to entry.
These services usually provide a graphical user interface with real-time monitoring and point-and-click utilities. Selecting a reputable database-as-a-service provider can save your database administrators and IT teams valuable time by offering disaster recovery support, scalability, and performance.
There are a few ways database replication can be executed. The first and easiest way, snapshot replication, happens when data is copied in full from one database to another, either on the same server or a remote server. Merging replication requires that data from multiple databases be merged into one database. Last of all, transactional replication happens when a database is only updated when it receives data changes.
With fully managed dedicated database hosting from ScaleGrid, you can start implementing database replication measures in just a few clicks, right now. ScaleGrid enables you to deploy, monitor, backup, and scale databases like MySQL, PostgreSQL, MongoDB® database and Redis™. With ScaleGrid, you can confidently focus on your product, automating much of the day-to-day database administrative tasks. With access to advanced management tools and the unparalleled support ScaleGrid has to offer, your organization can reduce costs by up to 75 percent.
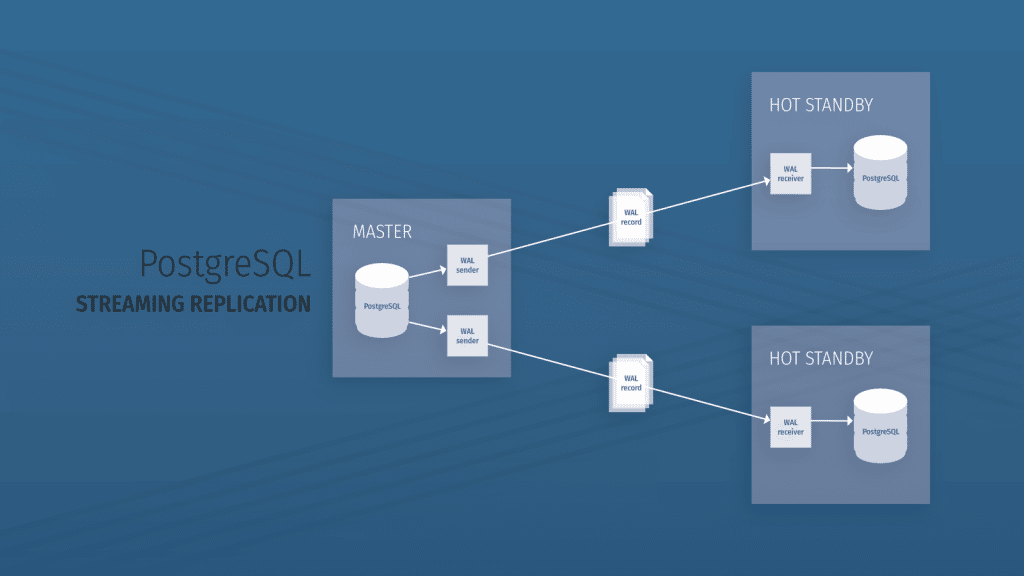
You can also read our previous blog post about replication in PostgreSQL where we compare logical with streaming replication.
To see how ScaleGrid stacks up against competitors like Azure, Amazon RDS, and DigitalOcean Managed Databases, visit here.
Key takeaways
Now that you have learned what database replication is, how distributed database replication systems can benefit your organization, and how to begin practicing it, there is no time like the present to start replicating your data. Database replication, if done correctly, can save organizations significant amounts of time, money, and resources. Optimizing your data replication system can make your applications faster, more powerful, and highly available. Data replication minimizes downtime and has disaster recovery built in. Be sure to identify your organization’s key data requirements so you can pick a plan that produces consistent results.
Downtime and data loss are avoidable risks, especially when you can depend on a professional database management service like ScaleGrid. You will find more on how ScaleGrid can help your organization with database management tools on the rest of our website.
As the old adage goes, don’t put all your eggs in one basket. The same is true of your data. IT professionals, developers, DevOps engineers, database administrators, and organizational stakeholders will thank you.



