In our previous posts in this series, we discussed the case for connection pooling and introduced PgBouncer. In this post, we will discuss its most popular alternative – Pgpool-II.
Pgpool-II is the swiss army knife of PostgreSQL middleware. It supports high-availability, provides automated load balancing, and has the intelligence to balance load between masters and slaves so write loads are always directed at masters, while read loads are directed to slaves. Pgpool-II also provides logical replication. While its use and importance has decreased as the inbuilt replication options improved on PostgreSQL server side, this still remains a valuable option for older versions of PostgreSQL. On top of all this, it also provides connection pooling!
Setting up Pgpool-II
Pgpool-II binaries are distributed through Pgpool-II’s repositories – you can read more about installation in this help doc. Once installed, we must configure Pgpool-II to enable the services we want, and connect to the PostgreSQL server. You can read more about it here.
To get a minimal pooling setup up, you must provide the following:
- The username and md5 encrypted password of the user(s) who’ll connect to Pgpool-II – this must be defined in a separate file, which can be easily generated using the pg_md5 util.
- Interfaces/IP-addresses and port number to listen to for incoming connections – this must be defined in the configuration file.
- The hostname of the backend server(s) [More than one server is specified only if we wish to use replication and/or load balancing].
- The services you wish to enable. By default, connection pooling is on, and other services are off in the configuration file installed with the binaries.
And that’s it – we are ready to go! While the configurations available with Pgpool-II might be more daunting at first sight, the folks behind Pgpool-II have really made it easy for us!
How it works
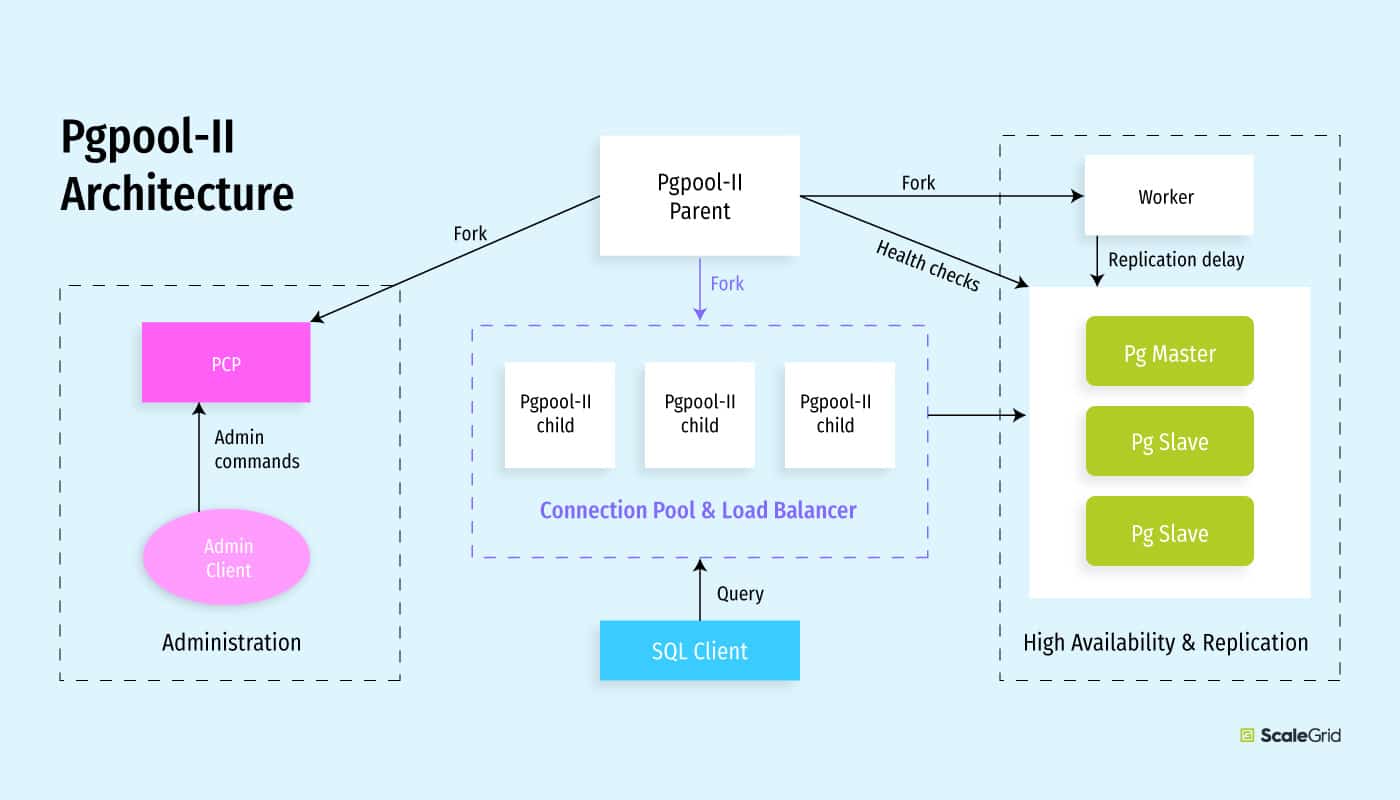
Pgpool-II has a more involved architecture than PgBouncer in order to support all the features it does. However, in this section, we will limit ourselves to describing how connection pooling works.
The Pgpool-II parent process forks 32 child processes by default – these are available for connection. The architecture is similar to PostgreSQL server: one process = one connection. It also forks the ‘pcp process’ which is used for administrative tasks, and beyond the scope of this post. The 32 children are now ready to accept connections. Like PgBouncer, these also emulate a PostgreSQL server – clients can connect with the exact same connection string as they would to a normal PostgreSQL server.
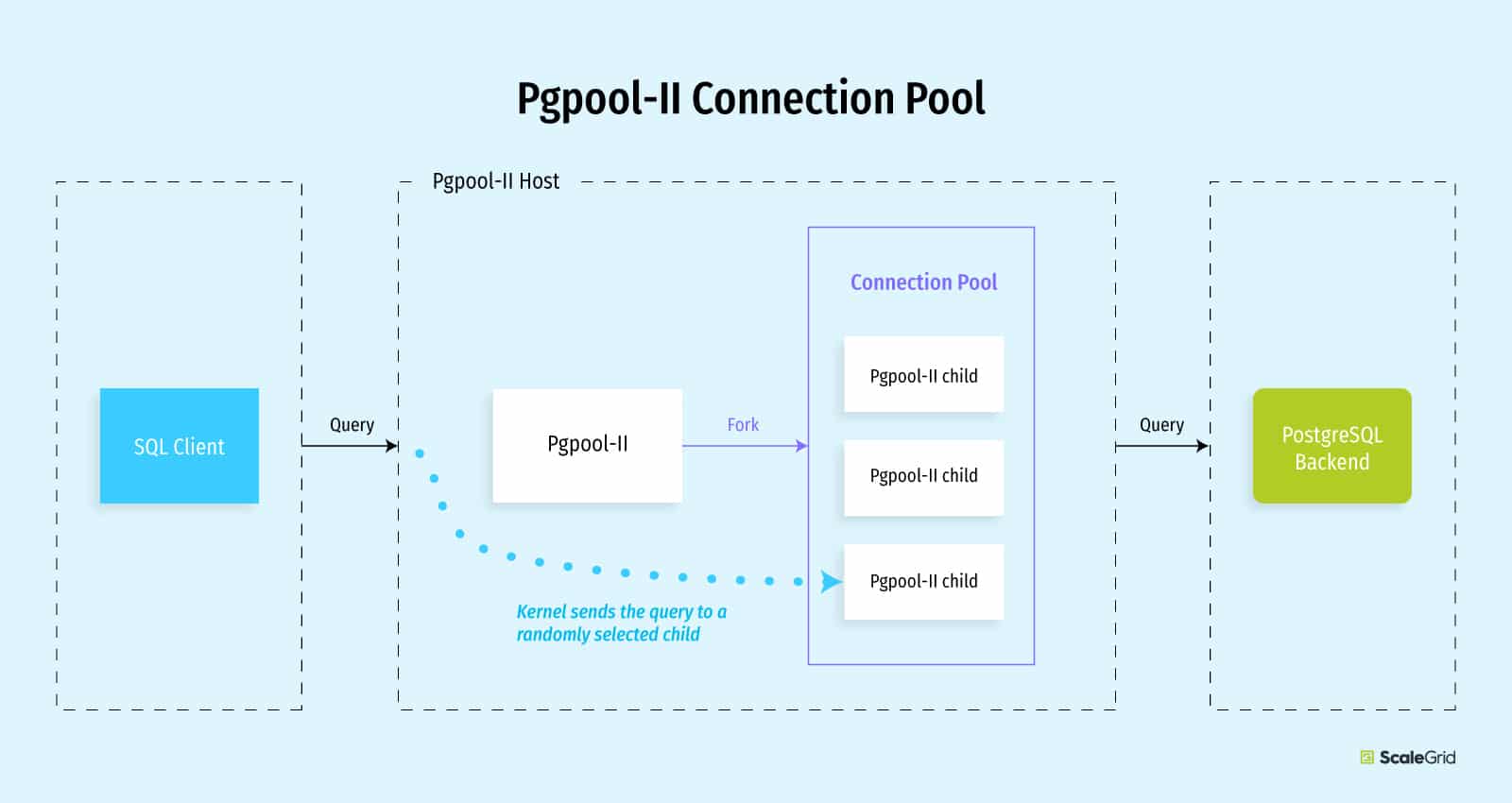
The kernel directs incoming connections to one of the child processes that have registered as listeners. Neither the main Pgpool-II process nor the end-users have any control over which child process responds to an incoming request. Any idle child can pick up the request. If no idle children are found, the connection request will be queued on the kernel side – this can cause applications like pgbench to hang, waiting for client connections.
Once an idle Pgpool-II child receives a connection request, it:
- Checks for the username in its password file. If not found, it rejects the connection.
- If the username is found, it checks the provided password against the md5 hash stored in this file.
- Once authentication succeeds, it checks if it already has a cached connection for this database+user combination.
- If it does, it returns the connection to the client. If it does not, it opens a new connection.
- All requests and responses pass through Pgpool-II while it waits for the client to disconnect.
- Once the client disconnects, Pgpool-II has to decide whether to cache the connection:
- If it has an empty slot, it caches it.
- If it doesn’t have an empty slot (that is, caching this connection would exceed the max_pool_size allowed), it will decide based on an internal algorithm.
- If it does decide to cache the connection, it will run the preconfigured reset query to clean up all session details and make it safe for reuse by a different client.
- Now the child process is free to pick up more connections.
Expert Tip
It is important to continuously monitor the health of your MySQL master and slave servers so you can detect potential issues and take corrective actions. Learn how.
What doesn’t Pgpool-II do?
Unfortunately, for those focusing only on connection pooling, what Pgpool-II doesn’t do very well is connection pooling, especially for a small number of clients. Because each child process has its own pool, and there is no way to control which client connects to which child process, too much is left to luck when it comes to reusing connections.
As you can see, Pgpool and PgBouncer have rather differing strengths – in our final post of the series, we will do a head-to-head testing, and feature comparison! Stay tuned!



