
Redis stands for REmote DIctionary Server, created in 2009 by Salvatore Sanfilippo. Memcached, on the other hand, was created in 2003 by Brad Fitzpatrick. Both Redis and Memcached are:
- NoSQL in-memory data structures
- Written in C
- Open source
- Used to speed up applications
- Support sub-millisecond latency
In 2014, Salvatore wrote an excellent StackOverflow post on when it makes more sense to use Memcached than Redis. In this post, we provide a current and detailed comparison between Redis and Memcached so that you can make an informed choice about their use in your application.
Infographic
This post has been condensed into the below infographic. With this infographic, you can easily visualize the results of this comparison to see which one comes out on top in different scenarios. If you want to read the comparison in text format, click here.
Documentation
To start off, Redis is much more comprehensively documented than Memcached. This makes it easier to learn, administer, and use.
Database Model
Redis is primarily a key-value store. While keys are binary strings, the advantage of Redis is that the value is not limited to only binary strings. They can be a variety of data structures that enable the storing of complex objects and provide a rich set of operations over them. Redis also provides for extensibility via Redis modules. Redis modules are extensions that provide for additional data structures and features not available within the core feature set. Here’s a sample of a few features that are now available as modules:
- Document Store
- Graph DBMS
- Search Engine
- Time Series DBMS
Memcached is a plain key-value store that only supports binary strings as values.
Data Structures
As mentioned above, Redis offers multiple data structure types allowing it to be extremely flexible to use, including Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, Bitfields, HyperLogLog, Geospatial indexes, and Streams. You can learn more about these in this Top Redis Use Cases by Core Data Structure Types article.
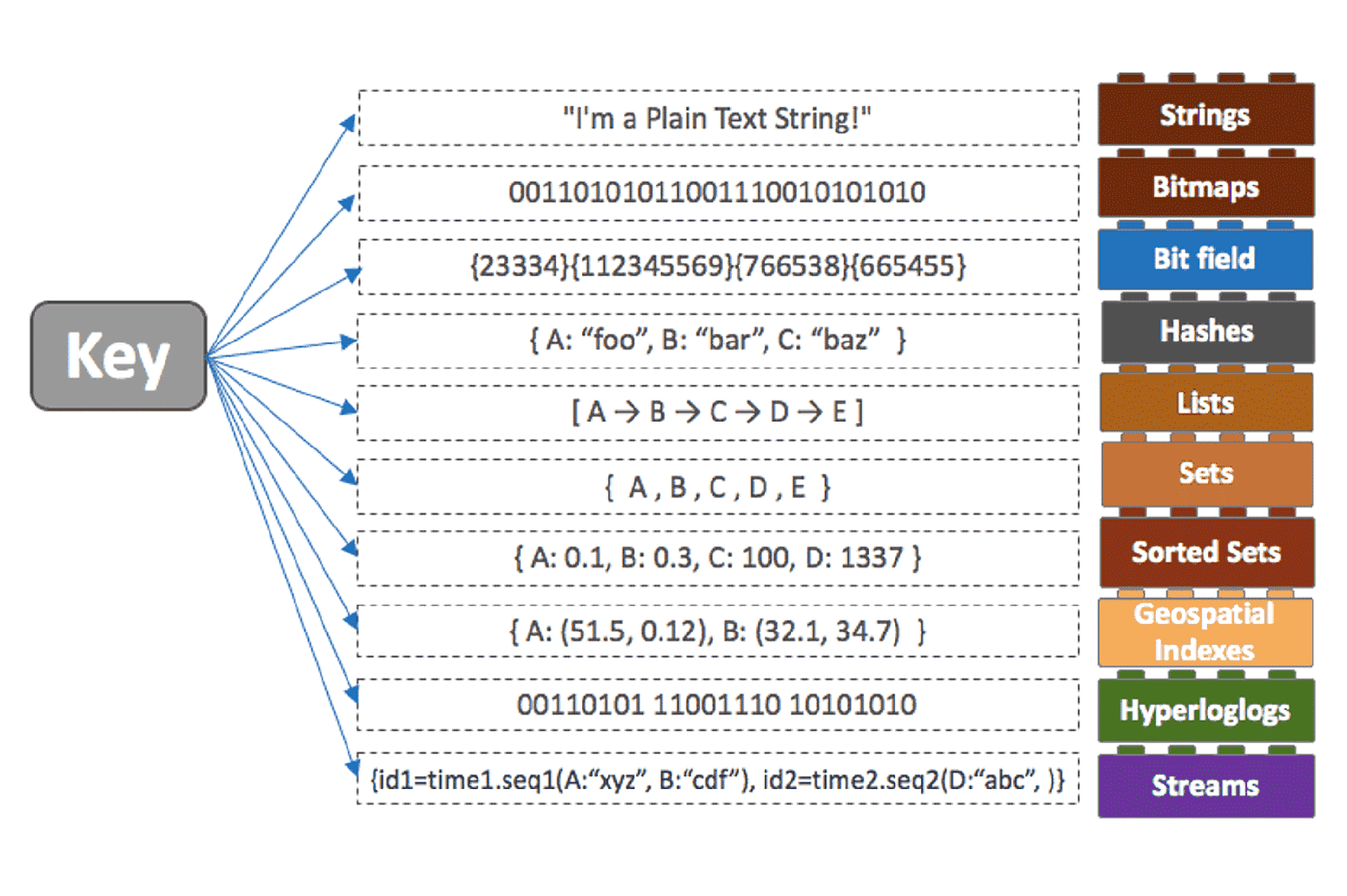
Image source: https://redis.com/redis-enterprise/data-structures/
Memcached only supports plain binary strings which are great for read-only data, so if you don’t need all the bells and whistles of Redis, Memcached is a simpler database for you to use.
Database Rank & Popularity
The greater popularity of a database results in a larger community of users, more discussions and user-generated tutorials, and more help and support through third-party tools such as DBaaS platforms and analysis tools to help optimize your deployments.
Redis is the 8th most popular database in the world as of February 2021, according to DB-Engines because of its simplicity, rich data structures, and great documentation. Memcached is currently ranked as the 28th most popular database. When Redis and Memcached are ranked with respect to key-value database models, Redis stands in 1st and Memcached comes 4th. However, if you are looking only for an open-source key-value database, or one that can be deployed on-premise, Memcached comes in 2nd as both Amazon DynamoDB and Microsoft Azure Cosmos DB are commercial databases that can only be deployed in the cloud.
Architecture
Redis and Memcached both follow client-server architecture. Clients populate the data in the server in the form of key-value.
Redis is single threaded where on the other hand Memcached has a multithreaded architecture. Memcached scales better on a system with more cores that can handle more operations if compute capacity is scaled. However, more than one Redis instance can be initiated on the same system to utilize additional cores.
Ease of Use
As explained above in the Database model section, Redis, being a multi-model database, can be used with any type of data model. In Redis, it is easy to write code as it simplifies complex tasks. Redis has advanced data structures and is not limited to simple string values. For instance, if your application stores data in sets and you want to keep track of sets in a list you can do this easily in Redis. A similar task on Memcached is not possible. But there are other ways to do the same tasks that will require more lines of code.
Memcached, on the other hand, only stores plain string values. So, the application is left to deal with the data structure complexity.
Data Partitioning
Redis supports partitioning of data across multiple node instances. Current users of Redis leverage different techniques like range partitioning, hash partitioning, and consistent hashing for data partitioning. In Redis, data partitioning can be implemented in three different ways:
- Client-side partitioning
- Proxy-assisted partitioning (example: twemproxy)
- Server-side partitioning with query routing within the cluster nodes
Memcached also supports data partitioning across multiple nodes, and consistent hashing is a recommended approach to ensure the traffic load is evenly distributed.
Supported Languages
Redis supports almost all of the most used programming languages, from high-level to low-level languages. Memcached however supports less number of languages compared to Redis but does support all the popular languages.
Memcached
- .Net
- C
- C++
- ColdFusion
- Erlang
- Java
- Lisp
- Lua
- OCaml
- Perl
- PHP
- Python
- Ruby
Redis
- C
- C#
- C++
- Clojure
- Crystal
- D
- Dart
- Elixir
- Erlang
- Fancy
- Go
- Haskell
- Haxe
- Java
- JavaScript (Node.js)
- Lisp
- Lua
- MatLab
- Objective-C
- OCaml
- Pascal
- Perl
- PHP
- Prolog
- Pure Data
- Python
- R
- Rebol
- Ruby
- Rust
- Scala
- Scheme
- Smalltalk
- Swift
- Tcl
- Visual Basic
Transactions
Redis “transactions” are executed with the three below guarantees:
- Transactions are serialized and executed sequentially
- Either all of the commands or none, are processed (atomic transactions)
- Optimistic locking offers an extra guarantee using check-and-set
Redis makes sure that only one command from one client machine is executed at once. All the commands in the transactions are executed when the “EXEC” command is called to ensure the atomicity.
Memcached, on the other hand, does not provide transaction management.
Replication
Redis offers a simple leader-follower (master-slave) replication that creates exact copies of the master instances, with these features:
- The master keeps on sending data commands to the slave as long as they are connected.
- If the connection breaks, the slave will follow partial resynchronization only copying the data that was missed during disconnection.
- If partial resynchronization is not possible, then it will try a full resynchronization.
You can also leverage the high availability features, Redis Sentinels or Redis Cluster, for advanced failover protection.
Native Memcached does not support replication, but you can use Repcached, a free open-source patch to achieve high availability for your deployment. It offers multi-master replication, and asynchronous data replication, and supports all Memcached commands.
Snapshots/Persistence
Snapshots are simply a read-only view of your database as it was at a certain point in time. Redis supports snapshots, and by default, Redis saves snapshots of the dataset on disk in a binary file called dump.rdb. You can manually call a snapshot, customize the frequency, or change the threshold for running the operation.
Here are the two persistence options Redis supports:
- RDB persistence
- AOF persistence
RDB stands for “Redis Database Backup”. It is a compact, point-in-time snapshot of the database at a specific time. It takes up less space, maximizes Redis performance, and is good for disaster recovery.
AOF stands for “Append Only File”. AOF keeps track of all the commands that are executed, and in a disastrous situation, it re-executes the commands to get the data back. This method takes more space as all the commands are executed again, and is not a very durable method of snapshotting.
Memcached on the other hand does not support on-disk persistence.
Server-Side Scripts
Lua is the embedded scripting language for your Redis server, available as of version 2.6, which lets you perform operations inside Redis to simplify your code and increase performance. The two main functions used to evaluate scripts using the Lua interpreter are:
- EVAL
- EVALSHA
When Lua script is being executed all other requests are blocked as shown in the figure below.
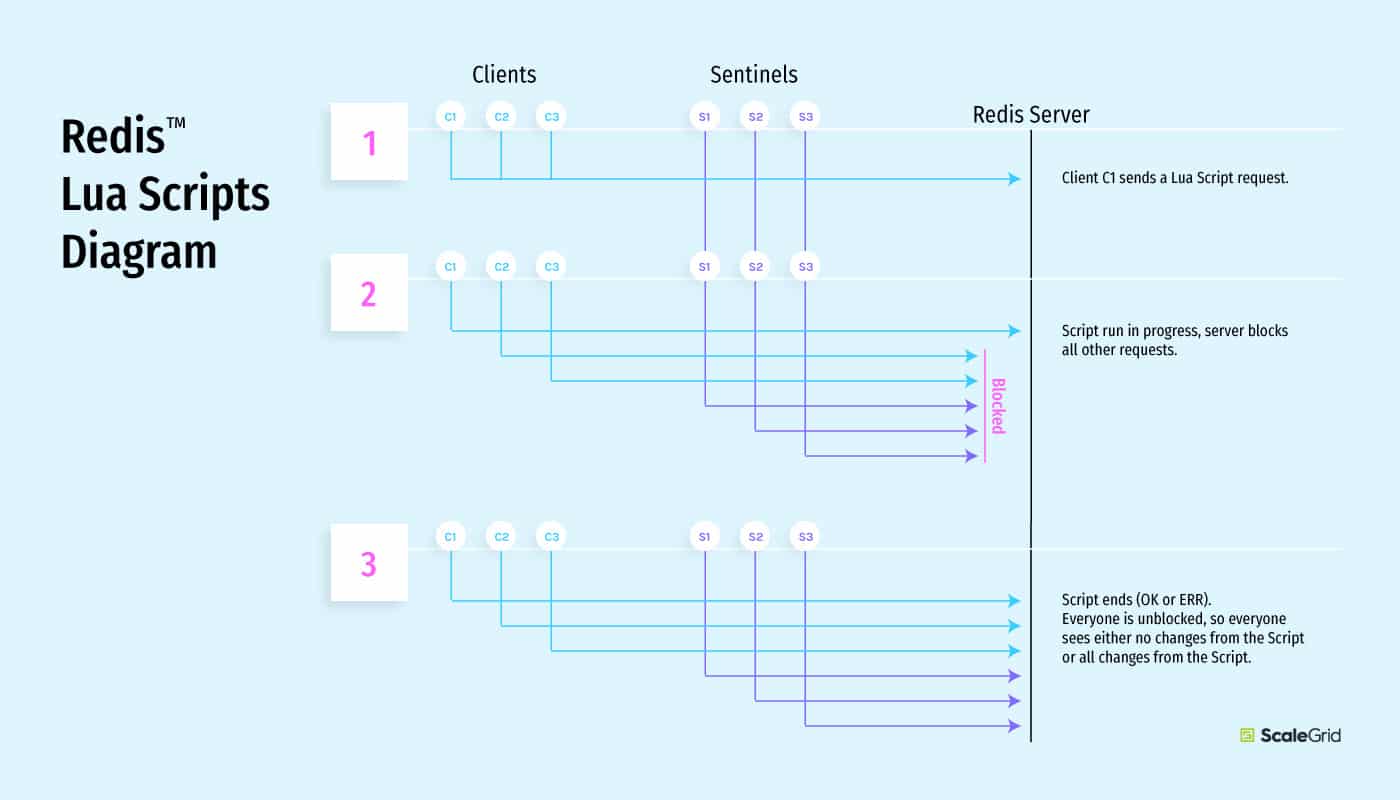
Redis also includes Lua scripts debugger in version 3.2 which makes writing complex scripts easier and helps in boosting performance.
Memcached does not support any server-side scripting.
Scalability
There are two techniques to horizontally scale your Redis database:
- Adding shards in Redis Clusters
- Adding nodes to a Redis HA (master/replica) setup
You can also vertically scale your Redis setup when you need more memory or computing. It can be done without downtime if you have a HA setup or you use Redis Cluster technology.
The Memcached server doesn’t provide a mechanism to distribute data across nodes (sharding). So, in Memcached, horizontal scalability is as simple as adding more nodes – the problem of partitioning your data into different shards will have to be done on the application/client level. There are some open-source tools that can help you with this.
Communication Protocol
Redis uses TCP as a network protocol and does not support UDP.
Memcached supports both the TCP and UDP communication protocols. Data is sent to the Memcached server in two forms:
- Text lines: Send commands and receive responses from the server.
- Unstructured data: Receive or send value information for a given key, and data is returned in the same format provided.
Supported Cache Eviction Policies
Redis supports different types of eviction policies. Let’s take a look at some.
- noeviction: In “noeviction” an error is returned when memory reaches it bound.
- allkeys-lru: Lru stands for “least recently used”. This policy removes the least recently used data.
- allkeys-lfu: Lfu stands for “least frequently used”. This policy removes the least frequently used data.
- allkeys-random: This policy removes the data randomly.
- volatile-lru: Volatile data is with expiration data set. This policy removes the least recently used volatile data.
- volatile-lfu: Volatile data is with expiration data set. This policy removes the least frequently used volatile data.
- volatile-random: This policy removes the volatile data randomly.
- volatile-ttl: “TTL” stands for time to live. This policy removes the data that have the shortest time to live.
Memcached uses LRU algorithm to evict data when space is required. It first searches for the already expired data to delete if expired data is not available the LRU algorithm is used.
Publish & Subscribe Messaging
Redis supports Pub/Sub messaging (publish and subscribe). There are three commands that are used for this purpose.
The client uses:
- Subscribe
- Unsubscribe
Subscribe and unsubscribe are used to get messages from a specific channel.
The server uses:
- Publish
The “publish” is used to push data to the clients.
Memcached does not support publish and subscribe messaging.
Streams Support
Redis supports Kafka-like streams with 5.0 or higher versions using a new data structure “Redis Streams”. Redis Streams has the concept of consumer groups, like Apache Kafka, that lets client applications consume messages in a distributed fashion, making it easy to scale and create highly available systems.
Memcached does not offer native support for Streams, but there are open-source library tools like Kafcache for stream processing at low latency.
Geospatial Support
Redis has a data structure called Geospatial indexes that stores the longitude and latitude data of a location. You can perform different operations on the geospatial data, like calculating the distance between two points or finding nearby places.
Memcached does not have any special data structures to handle geospatial data.
Performance
A performance comparison between in-memory key-value data stores is more of an intellectual exercise than of any practical importance – unless you are deploying systems at such a scale that this becomes interesting as a cost-saving measure. This is because such stores are IO bound and usually the network latency might play a bigger role in application perceived latency than the database latency.
A more practical performance aspect is storage efficiency – how much data can be packed in the same amount of memory. Even here, the internal data structures used by Redis vary based on the data size. So any discussion on performance between these databases should be taken with a pinch of salt.
Let’s take a look at some comparisons shown in a 2016 research paper. In this paper, the authors experiment with the widely used in-memory databases to measure their performance in terms of:
- The time taken to complete operations.
- How efficiently they use memory during operations.
Database versions used in the paper:
| Database | Version |
|---|---|
| Redis | 3.0.7 |
| Memcached | 1.4.14 |
Write Operation
While writing data, as you can see, in the table below Memcached shows exceptional speed even after the number of records moves up to a million.
The calculated time to write key-value pairs (ms)
| Number of records | ||||
|---|---|---|---|---|
| Database | 1,000 | 10,000 | 100,000 | 1,000,000 |
| Redis | 34 | 214 | 1,666 | 14,638 |
| Memcached | 23 | 100 | 276 | 2,813 |
Read Operation
Reading data stays almost consistent in Redis even for a million records but in Memcached, as the number of records goes up the time also increases a little bit.
The elapsed time to read value corresponding to a given key per database (ms)
| Number of records | ||||
|---|---|---|---|---|
| Database | 1,000 | 10,000 | 100,000 | 1,000,000 |
| Redis | 8 | 6 | 8 | 8 |
| Memcached | 9 | 14 | 14 | 30 |
Memory Use
While discussing memory usage, Redis is always the best as you can see in the results.
Memory usage of in-memory databases for write operation (MB)
| Number of records | ||||
|---|---|---|---|---|
| Database | 1,000 | 10,000 | 100,000 | 1,000,000 |
| Redis | 2.5 | 3.8 | 4.3 | 62.7 |
| Memcached | 5.3 | 27.2 | 211 | 264.9 |
As you can see Redis is better than Memcached.
Memory usage of in-memory databases for delete operation (MB)
| Number of records | ||||
|---|---|---|---|---|
| Database | 1,000 | 10,000 | 100,000 | 1,000,000 |
| Redis | 0 | 0 | 0 | 0 |
| Memcached | 2.2 | 2.1 | 2.2 | 2.2 |
Managed Services/Support
The greater popularity and community of Redis has also driven the need for managed services, hosting, and support. Popular managed database providers for Redis™* include ScaleGrid, Redis, AWS Elasticache, Azure Cache, and DigitalOcean. This page provides a great comparison of the top providers for Redis™. Redis also has extensive internal reporting tools like cache hits, memory usage, ops, and even a slow query log.
Managed services for Memcached are far less available, but is still supported through Amazon Elasticache.
Transport Layer Security (TLS) Support
Redis has native TLS support starting Redis 6.0. Earlier versions of Redis recommended the use of stunnel for providing TLS support.
Memcached 1.5.13 and above versions support authentication and encryption via TLS. This feature is still in experimental stages.
Authentication
Up to Redis 5.x, Redis only supported a simple password-based authentication. This password was stored in plaintext on the server. Redis in version 6.0 onwards supports a fully featured ACL.
Memcached version 1.4.3 and greater has SASL support. Previously Memcached had no authentication layer.
Summary
Redis and Memcached are both great and have applications in different areas. Redis being developed later has many advanced functionalities and has great documentation and community.
Read also:
6 Crucial Redis Monitoring Metrics You Need To Watch
Get To Know the Redis Database: Iterating Over Keys
Redis vs MongoDB
*Redis is a registered trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by ScaleGrid is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and ScaleGrid.



