
In this post, we’re comparing two of the most popular NoSQL databases: Redis (in-memory) and MongoDB® (Percona memory storage engine).
Redis: A Fast and Powerful In-Memory Key-Value Store for Caching
Redis is a popular and very fast in-memory database structure store primarily used as a cache or a message broker. Being in-memory, it’s the fixed data structure store of choice when application performance demands quick response times, making it an ideal solution for real-time applications and real-time analytics.
Redis’s performance advantages over relational databases make it a compelling popular choice for scenarios requiring rapid data access disk storage and processing, offering a wide range of capabilities to cater to diverse caching needs.
MongoDB®: A Scalable On-Disk Document Store with Rich Query Language
MongoDB® is an on-disk document store that provides a JSON interface to data and has a very rich query language. Known for its speed, efficiency, and scalability, it’s currently the most popular NoSQL database used today.
However, being an on-disk database, it can’t compare favorably to an in-memory database like Redis in terms of absolute performance for certain use cases. But, with the high availability of the in-memory storage engines for MongoDB®, a more direct comparison becomes feasible, allowing users to evaluate the key differences in their capabilities.
Redis’s performance advantages over relational databases make it a compelling choice for scenarios requiring rapid data access and processing.
Percona Memory Storage Engine for MongoDB®

Starting in version 3.0, MongoDB® provides an API to plug in the storage engine of your choice. A storage engine is the component of the database that will store data and is responsible for managing how the data is stored, both in-memory and on disk.
MongoDB® supports an in-memory storage engine; however, it’s currently limited to the product’s Enterprise edition.
In 2016, Percona released an open-source in-memory persistent storage engine for the MongoDB® Community Edition called the Percona Memory Engine for MongoDB®. It is a variation of the WiredTiger storage engine but with no persistence to disk.
With the Percona Memory Engine, users can seamlessly integrate in-memory capabilities into their existing MongoDB® process, enhancing the performance and scalability of their applications. Moreover, the Percona Memory Engine’s compatibility with various MongoDB® drivers ensures smooth integration with existing applications, simplifying the migration process.
Redis® vs. MongoDB®: A Comparison of Caching Solutions
With an in-memory MongoDB® storage engine in place, we have a level playing field between Redis® and MongoDB®. So, why do we need to compare the two? Let’s look at the advantages of each of them as a caching solution.
Let’s look at Redis first.
Advantages of Redis as a Cache
Redis is a well-known caching solution that excels at it. It isn’t a plain cache solution – it has advanced data structures that provide many powerful ways to save and query data, including aggregation, that can’t be achieved with a vanilla key-value store. Redis is fairly simple to set up, use, and learn.
Additionally, you can opt to set up persistence in Redis, making cache warming hassle-free in the event of a crash.
Redis offers remarkable application performance and low latency, making it ideal for scenarios requiring real-time data access and real-time analytics.
Its in-memory nature ensures data storage and lightning-fast retrieval of frequently accessed data. Moreover, Redis supports various data types, allowing developers to handle complex data models effectively.
Redis is also highly versatile as a cache. It can be used as a session store for applications, providing a fast and reliable way to manage user sessions.
Furthermore, Redis has an active and vibrant community that regularly contributes new features and improvements, ensuring that the caching solution stays up-to-date with evolving requirements. The flexible and adaptable schema of Redis makes it a popular choice for a wide range of caching needs.
Disadvantages of Redis®:
However, there are some drawbacks to using Redis. Firstly, it doesn’t have inbuilt encryption on the wire, which may pose security concerns for some applications. Secondly, Redis lacks role-based account control (RBAC), potentially making access management more challenging.
Furthermore, while Redis is an excellent choice for certain database architecture and deployment scenarios, it doesn’t offer a seamless, mature clustering solution, which can be a concern for large-scale cloud deployments. As a disk-based database, Redis may face limitations in handling massive datasets compared to a disk database like MongoDB®.
Redis disadvantages keywords: Redis, inbuilt encryption, role-based account control data replication, clustering solution, large-scale cloud deployments, disk database
Advantages of MongoDB® as a Cache
On the other hand, MongoDB® serves as a more traditional relational database, with advanced data manipulation features such as aggregations and map-reduce, accompanied by a rich query language. MongoDB offers SSL, RBAC, and built-in scale-out capabilities, ensuring robust security and seamless scalability.
Additionally, if you are already using MongoDB® as your primary database, operational and development costs drop as you only have one database to learn and one document database to manage.
MongoDB® can be an excellent in-memory storage solution, leveraging its caching capabilities to speed up read-intensive operations. When deployed as a cache, MongoDB® can significantly reduce the response time for frequently accessed data, resulting in better overall application performance.
Moreover, MongoDB® provides various optimization tools to fine-tune the data structure and caching configuration and improve data access efficiency.
Disadvantages of MongoDB®:
Nevertheless, there is one significant disadvantage of using MongoDB® as a cache. With an in-memory engine, it offers no persistence until it’s deployed as a replica set with persistence configured on the read replica(s). This lack of persistence might be a concern for certain use cases where data durability is essential.
Comparing Redis® and MongoDB® Performance
In this post, we’ll focus on quantifying the performance differences between Redis and MongoDB®. A qualitative comparison and operational differences will be covered in subsequent posts.
- Redis performs considerably better for reads for all sorts of workloads, and better for writes as the workloads increase.
- Even though MongoDB® utilizes all the cores of the system, it gets CPU bound comparatively early. While it still had compute available, it was better at writes than Redis.
- Both databases are eventually compute-bound. Even though Redis is single-threaded, it (mostly) gets more done with running on one core than MongoDB® does while saturating all the cores.
- Redis, for non-trivial data sets, uses a lot more RAM compared to MongoDB® to store the same amount of data.
Configuration
We used YCSB to measure the performance, and have been using it to compare and benchmark the performance of MongoDB® on various cloud providers and configurations in the past. We assume a basic understanding of YCSB workloads and features in the test rig description.
- Database instance type: AWS EC2 c4.xlarge featuring 4 cores, 7.5 GB memory, and enhanced networking to ensure we don’t have any network bottlenecks.
- Client Machine: AWS EC2 c4.xlarge in the same virtual private cloud (VPC) as the database servers.
- Redis: Version 3.2.8 with AOF and RDB turned off. Standalone.
- MongoDB®: Percona Memory Engine based on MongoDB® version 3.2.12. Standalone.
- Network Throughput: Measured via iperf as recommended by AWS: Test Complete. Summary Results: [ ID] Interval Transfer Bandwidth Retr [ 4] 0.00-60.00 sec 8.99 GBytes1.29 Gbits/sec146 sender [ 4] 0.00-60.00 sec 8.99 GBytes1.29 Gbits/sec receiver
- Workload DetailsInsert Workload:100 % Write – 2.5 million records Workload A: Update heavy workload – 50%/50% Reads/Writes – 25 million operations Workload B: Read mostly workload – 95%/5% Reads/Writes – 25 million operations
- Client Load: Throughput and latency are measured over incrementally increasing loads generated from the client. This was done by increasing the number of YCSB client load threads, starting at 8 and growing in multiples of 2
Redis® vs MongoDB® Benchmark Results
Workload B Performance
Since the primary use case for in-memory databases is cache, let’s look at Workload B first.
Here are the throughput/latency numbers from the 25 million operations workload and the ratio of reads/writes was 95%/5%. This would be a representative cache reading workload:
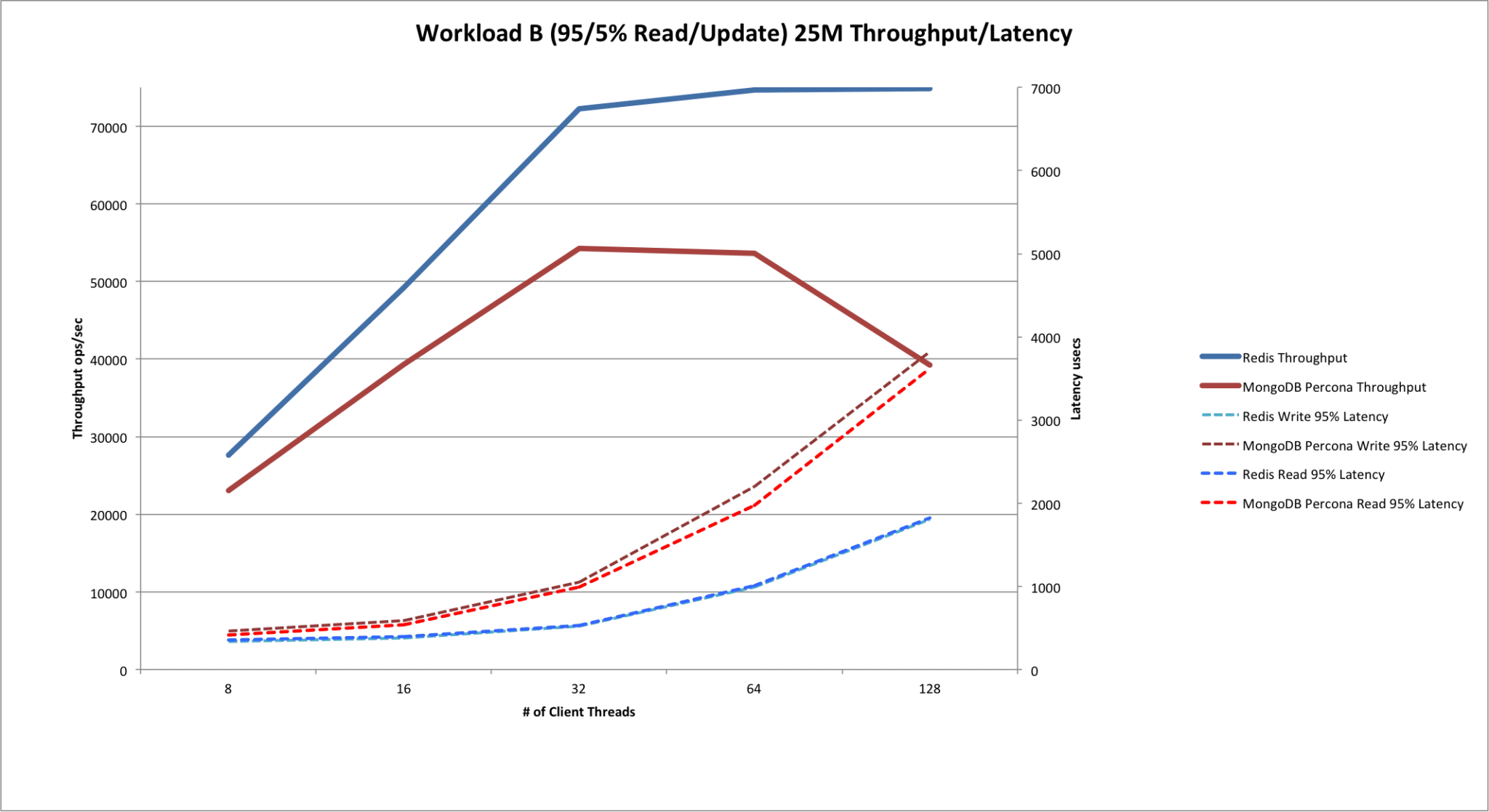
Note: Throughput is plotted against the primary axis (left), while latency is plotted against the secondary axis (right).
Observations during the Workload B run:
- For MongoDB®, the CPU was saturated by 32 threads onwards. Greater than 300% usage with single-digit idle percentages.
- For Redis®, CPU utilization never crossed 95%. So, Redis® was consistently performing better than MongoDB® while running on a single thread, while MongoDB® was saturating all the cores of the machine.
- For Redis®, at 128 threads, runs failed often with read-timeout exceptions.
Workload A Performance
Here are the throughput/latency numbers from the 25 million operations workload. The ratio of reads/writes was 50%/50%:
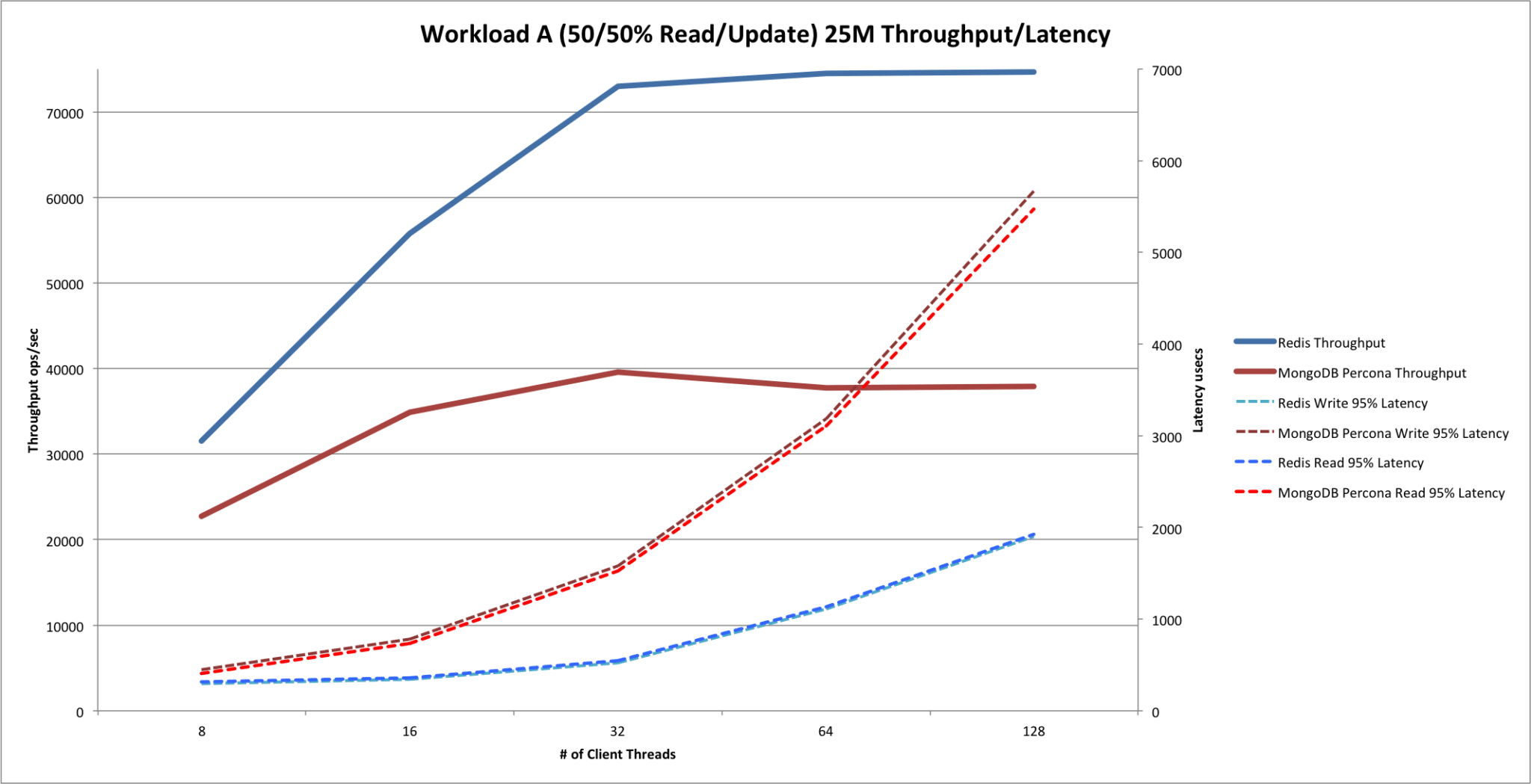
Note: Throughput is plotted against the primary axis (left), while latency is plotted against the secondary axis (right).
Observations during the Workload A run:
- For MongoDB®, the CPU was saturated by 32 threads onwards. Greater than 300% usage with single-digit idle percentages.
- For Redis®, CPU utilization never crossed 95%.
- For Redis®, by 64 threads and above, runs failed often with read-timeout exceptions.
Insert Workload Performance
Finally, here are the throughput/latency numbers from the 2.5 million record insertion workload. The number of records was selected to ensure the total memory was used in the event Redis did not exceed 80% (since Redis is the memory hog, see Appendix B).
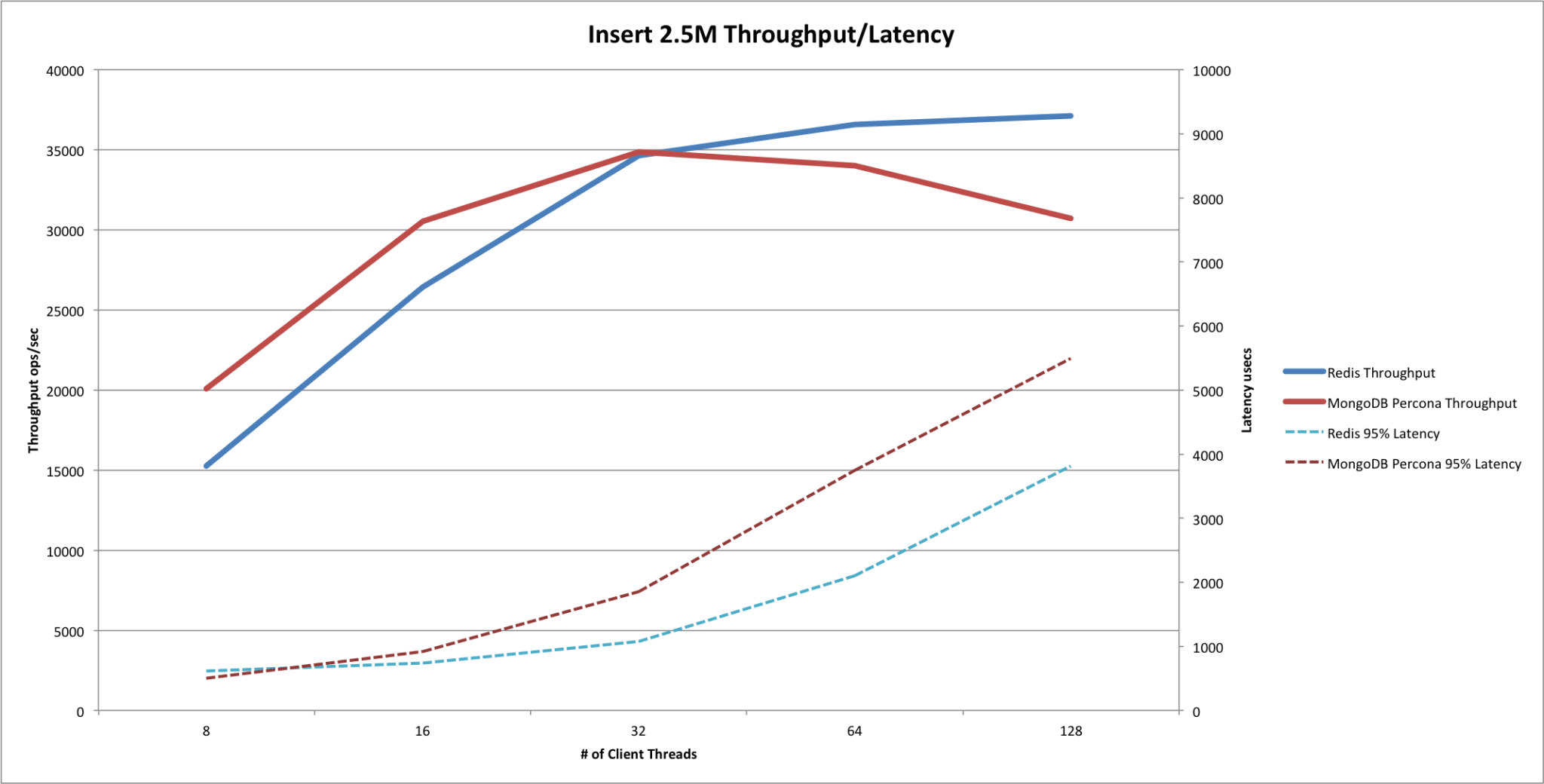
Note: Throughput is plotted against the primary axis (left), while latency is plotted against the secondary axis (right).
Observations during the Insert Workload run:
- For MongoDB®, the CPU was saturated by 32 threads onwards. Greater than 300% usage with single-digit idle percentages.
- For Redis®, CPU utilization never crossed 95%.
Appendices
A: Single-Thread Performance
I had a strong urge to find this out – even though it’s not very useful in real-world conditions: who would be better when applying the same load to multiple nodes, each of them from a single thread? That is, how would a single-threaded application perform?
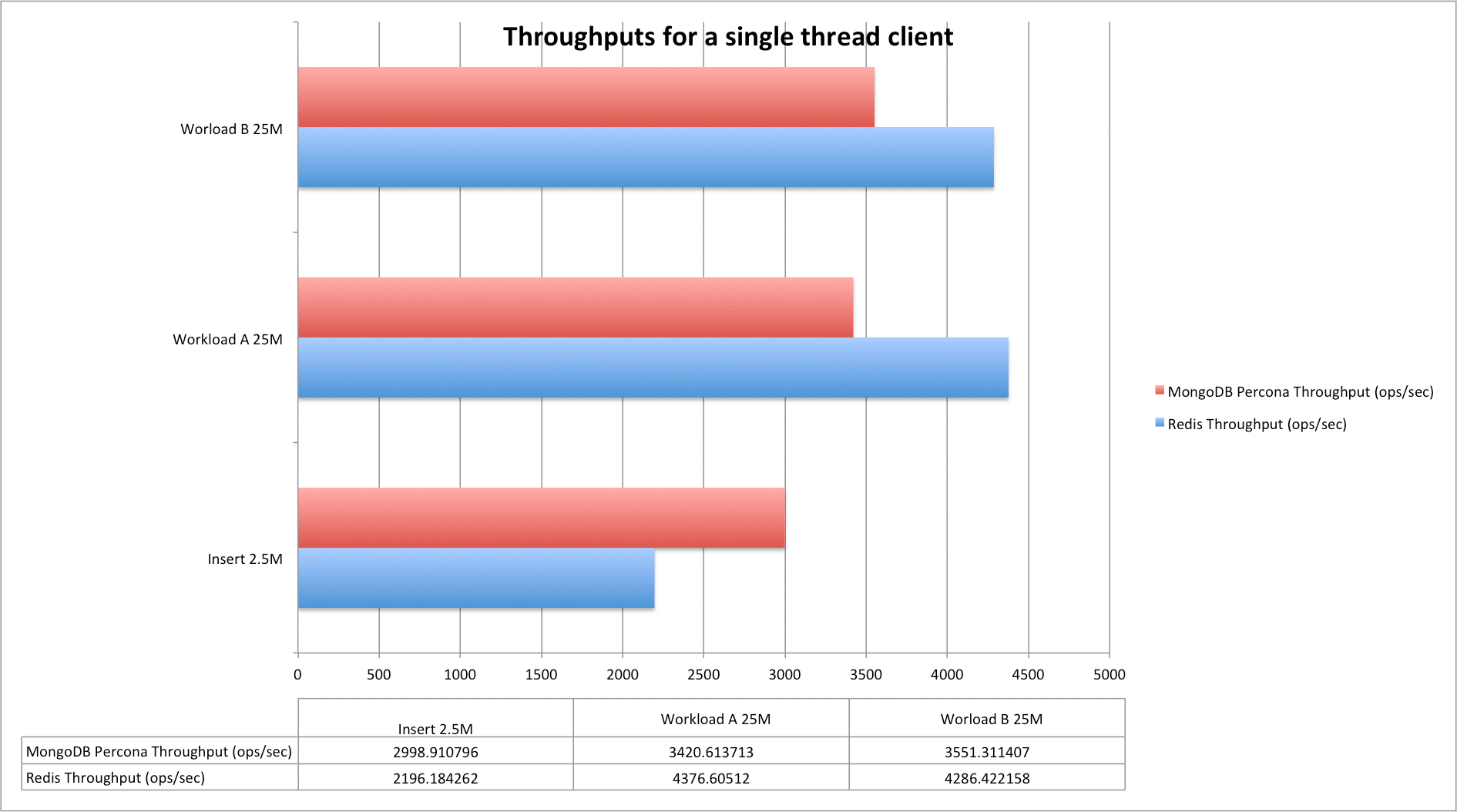
B: Database Size
The default format of records inserted by YCSB is: each record is of 10 fields and each field is 100 bytes. Assuming each record to be around 1KB, the total expected size in memory would be upwards of 2.4GB. There was a stark contrast in the actual sizes as seen in the databases.
MongoDB®
So, the space taken is ~2.7GB which is pretty close to what we expected.
Redis®
At peak usage, Redis® seems to be taking around 5.72G of memory i.e. twice as much memory as MongoDB takes. Now, this comparison may not be perfect because of the differences in the two databases, but this difference in memory usage is too large to ignore.
YCSB inserts stored data record in a hash in Redis, and an index is maintained in a sorted set. Since an individual entry is larger than 64, the hash is encoded normally and there is no savings in space. Redis performance comes at the price of increased memory footprint.
This, in our opinion, can be an important data point in choosing between MongoDB® and Redis® – MongoDB® might be preferable for users who care about reducing their memory costs.
C: Network Throughput
An in-memory database server is liable to be either compute-bound or network I/O-bound, so it was important throughout the entire set of these tests to ensure that we were never getting network-bound.
Measuring network throughput while running application throughput tests adversely affects the overall throughput measurement.
So, we ran subsequent network throughput measurements using iftop at the thread counts where the highest write throughputs were observed. This was found to be around 440 Mbps for both Redis® and MongoDB® at their respective peak throughput.
Given our initial measurement of the maximum network bandwidth to be around 1.29 Gbps, we are certain that we never hit the network bounds. It only supports the inference that if the Redis cluster were multi-core, we might get much better numbers.
Read Also:
6 Crucial Redis Monitoring Metrics You Need To Watch
How to enable logging for Mongoose and the MongoDB® Node.JS driver
Get To Know the Redis Database: Iterating Over Keys
Cassandra vs MongoDB®



